The DAIR Program is longer accepting applications for cloud resources, but access to BoosterPacks and their resources remains available. BoosterPacks will be maintained and supported until January 17, 2025.
After January 17, 2025:
Screenshots should remain accurate, however where you are instructed to login to your DAIR account in AWS, you will be required to login to a personal AWS account.
Links to AWS CloudFormation scripts for the automated deployment of each sample application should remain intact and functional.
Links to GitHub repositories for downloading BoosterPack source code will remain valid as they are owned and sustained by the BoosterPack Builder (original creators of the open-source sample applications).
This Sample Solution, from the Automated Document Classification and Discovery BoosterPack, demonstrates how FormKiQ used Micronaut, Apache Kafka, Tesseract Optical Character Recognition (OCR), Elasticsearch, and Natural Language Pprocessing (NLP) to automatically categorize and tag documents based on their content, allowing users to search and retrieve documents quickly.
Problem Statement
Many organizations would benefit from the ability to retrieve specific documents from a document repository while requiring additional context to discover and categorize results. Currently, this is achieved either through manual searches or by the manual input of document metadata. Both methods are expensive, inefficient, and time-consuming, so we’ve created a better way!
Automated Document Classification and Discovery would provide a significant benefit to specific industries. For example, law firms and legal services need to be able to respond to and review document requests and other legal industry workflows. These requests are often time-sensitive, and the costs can be prohibitive. Other beneficiaries of this technology would be professional services such as engineering and construction, where document control is an essential part of , and where human error or delays can be costly, often impacting an organization’s ability to fulfill its contractual obligations.
The impact of these high costs and time delays not only affect the financial health of the organization itself, but in the case of industries such as health care, these issues can have a negative impact on broader society as well.
Traditional solutions have relied on standard operating procedures and workflows with multiple manual steps. These processes are time-consuming and resource-intensive, and provide lower accuracy due to human error and inconsistency in classification.
Using OCR, NLP, and Full-Text Search, this sample solution automates the creation of document metadata, reducing time spent, the possibility of error, and the overall total cost.
Automated Document Classification and Discovery in the DAIR Cloud – Sample Solution
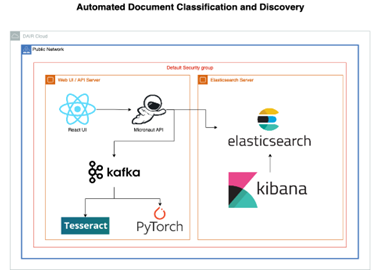
Sample Solution Overview Diagram
The diagram below illustrates the structure of the Sample Solution.
Component Descriptions
Significant components used in the Sample Solution are summarized in the table below:
Component
Description
React UI Application
A web-based user interface for interacting with the application.
Kafka
A distributed streaming platform used to coordinate the processing of documents through the multi-step workflow.
Micronaut Framework
Java Virtual Machine-based web framework used to process API requests, listen for and process Apache Kafka messages, and write documents to the Elasticsearch server.
Tesseract
Tesseract is an open-source OCR engine that is widely used for recognizing text within digital images.
PyTorch
PyTorch is an open-source machine learning framework primarily used for building and training deep neural networks. Its purpose is to provide a flexible and easy-to-use platform for developers to build complex models for tasks such as image recognition, NLP, and more.
Elasticsearch
Elasticsearch is a distributed, open-source search and analytics engine designed to store, search, and analyze large volumes of structured and unstructured data in real-time. It enables users to easily perform complex queries and analysis on their data.
How to Deploy and Configure
If you’re a DAIR participant, you can deploy the Sample Solution by navigating to the Automated Document Classification and Discovery section of the Boosterpack Catalogue page following the instructions on that page for deploying a new instance of the Solution.
The assumptions or prerequisite steps before deploying the sample application require that you have set up:
a security group rule that allows HTTP (port 80) and HTTPS (port 443) connections into VMs spun up in the DAIR Cloud from all external sources (0.0.0.0/0).
a security group rule that allows the default VPC network (172.31.0.0/16) to connect to the Elasticsearch API (port 9200).
a security group that allows you to SSH (TCP port 22) into VMs that are spun up in the DAIR Cloud from the IP with which you are accessing the VM
your SSH private key to log in to your DAIR BoosterPack VMs
Ensure that you are logged in to your DAIR AWS account with instructions provided to you by the DAIR team.
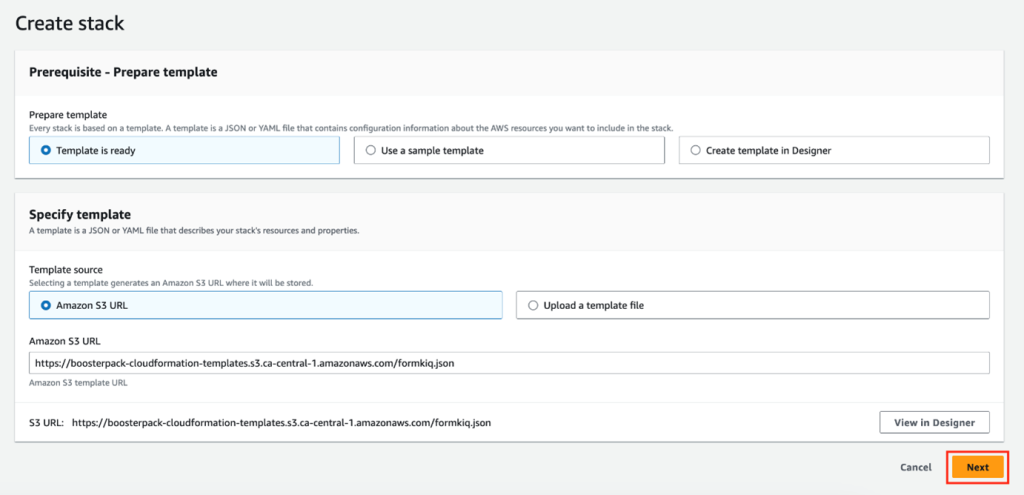
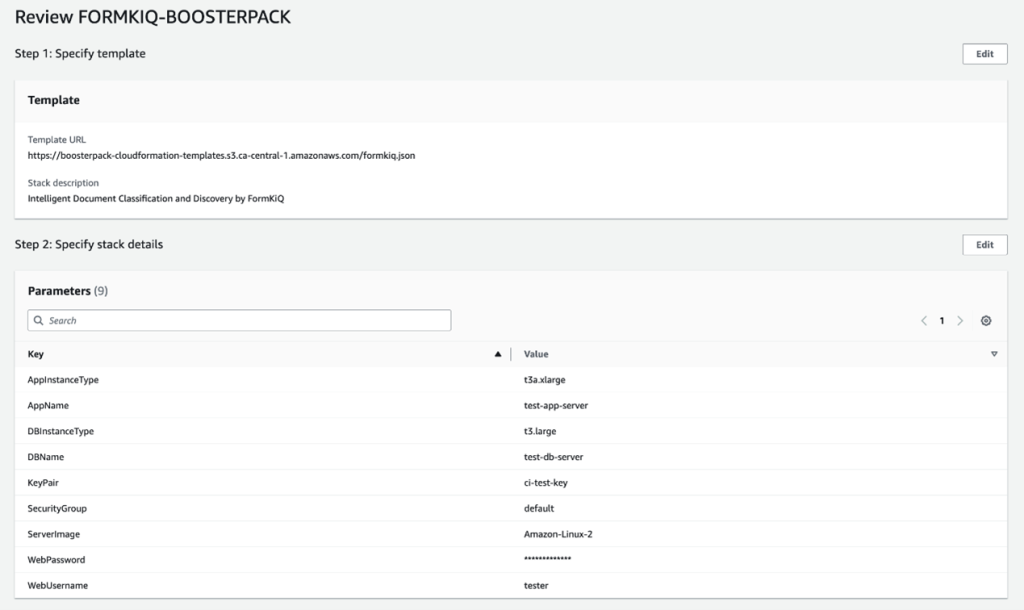
Click DEPLOY to launch the BoosterPack using AWS CloudFormation stack.
Fill out the configuration form.
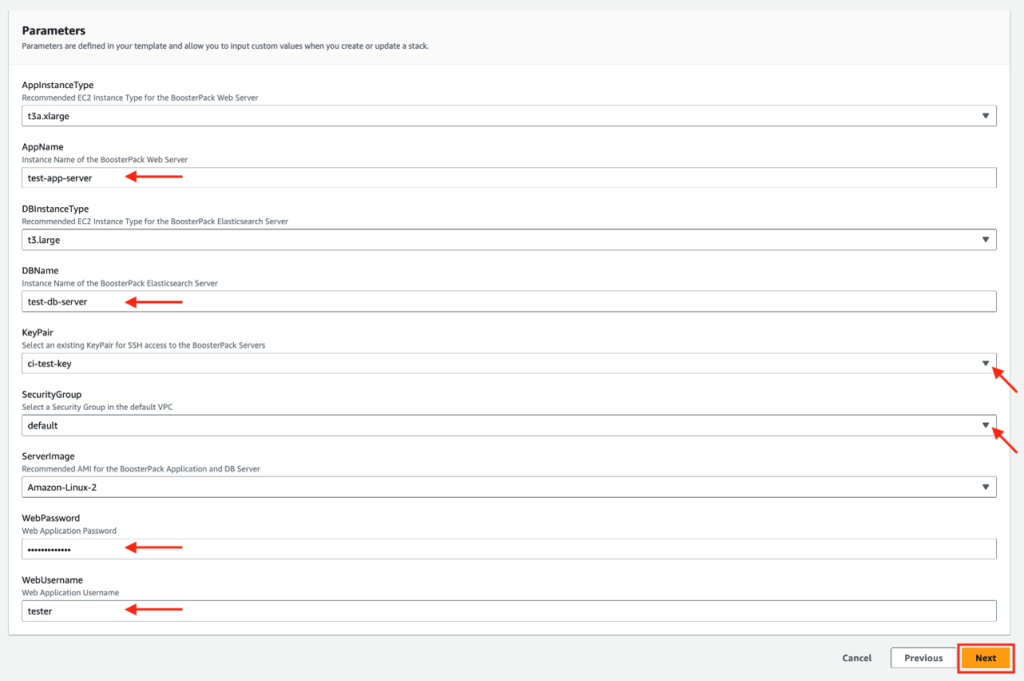
Click Next to go to CloudFormation step 2 and fill out the parameter configuration form. In the AppName and DBName fields, provide unique instance names for your web application and database servers respectively.
Also configure your web application password and username by filling the WebPassword and WebUsername fields respectively. The rest of the form is completed using the drop-down options. Please note that other parameters (such as “ServerImage”, “AppInstanceType” and “DBInstanceType”) are pre-configured and cannot be modified.
Note: Ensure you choose secure WebUsername and WebPassword parameters.
Once you are done, click NEXT to go to CloudFormation step 3. This section is for configuring additional/advanced options which are not required in our use case. Simply click “Next” at the bottom of the page to skip step 3 and get to the final CloudFormation step 4.
The final section allows you to review existing BoosterPack configurations and provides options for making configuration changes, using the “Edit” button, if needed. Once satisfied with the existing configuration, click “Submit” at the bottom of the page to deploy the BoosterPack.
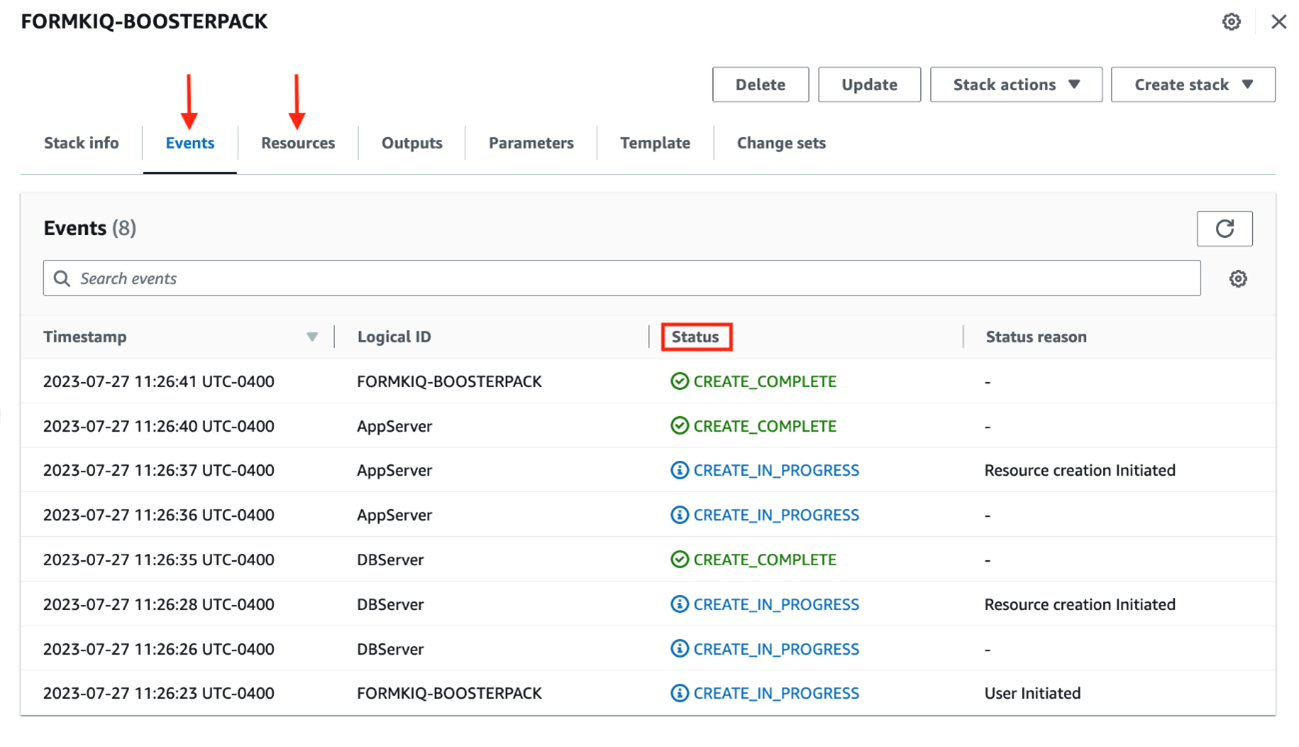
The BoosterPack deployment will start by creating 2 new instances (including the web application server and database server) and the deployment automation will follow. However, you can only monitor the status of the AWS instances through the “Events” and “Resources” tab of the CloudFormation page and you will need to subsequently log in to the web application and database servers to confirm each deployment automation status.
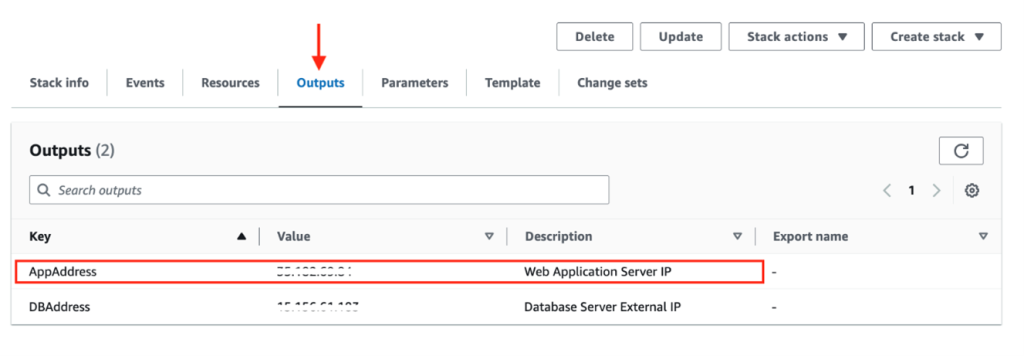
Make a note of the “Web Application Server IP” value found under the “Outputs” tab of the BoosterPack CloudFormation page. This is the external/public IP of the web application server of the BoosterPackbeing created. You will need this IP address to access the web interfaces of the sample application or to login to the server using SSH.
From a shell/terminal that has SSH enabled, log in to the web application server with the following SSH command:
ssh -i key_file.pem ec2-user@IP
Replace “key_file” with the private key of the SSH key pair selected in the CloudFormation parameter configuration form and replace “IP” with the IP Address value obtained from the CloudFormation output.
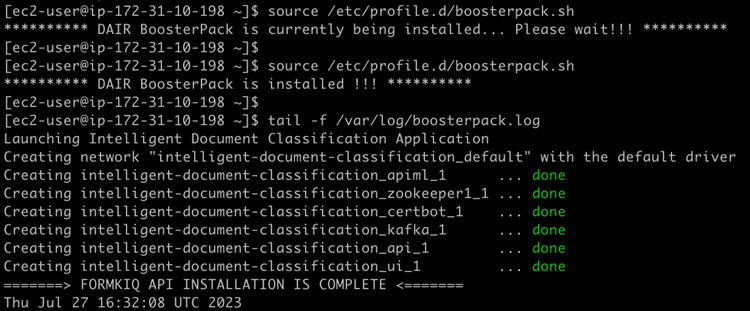
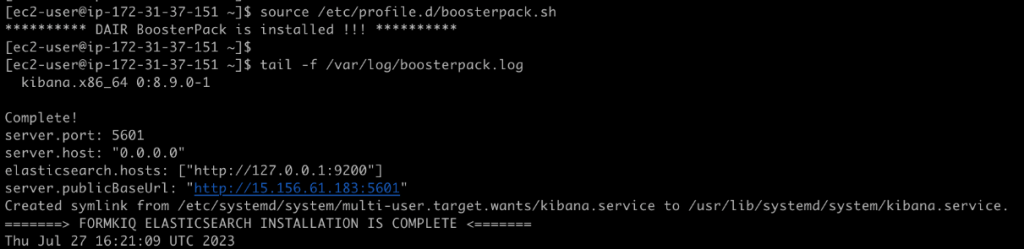
Once successfully logged in to the application server, you can monitor the status of the deployment automation script with the following commands:
source /etc/profile.d/boosterpack.sh
tail -f /var/log/boosterpack.log
You can also follow the same steps to check the deployment automaton status of the database server, which typically takes less time compared to the web application server.
The full BoosterPack deployment, including automation scripts on both web application and database servers, can take up to 15 minutes to complete.
Configuration and Application Launch
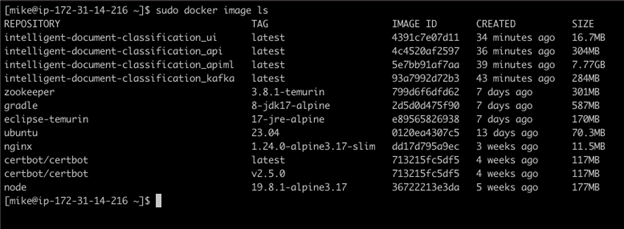
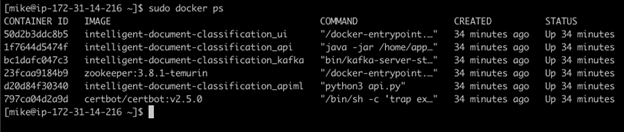
The application launches automatically post-instantiation and can be verified (as running) using the Docker command in the command prompt as shown below:
sudo docker image ls
sudo docker ps
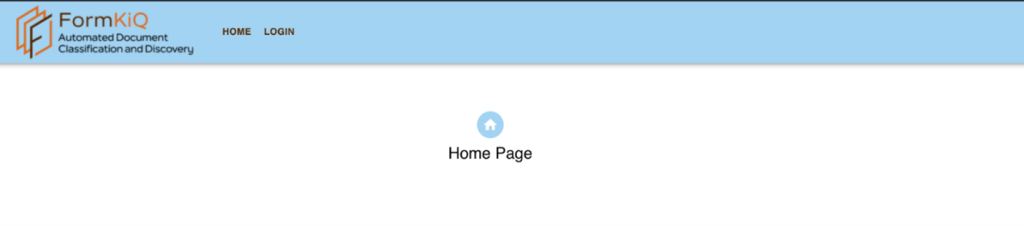
The user interface is accessible via a web browser, using a secure URL that includes the web application server IP address (AppAddress) previously obtained from the CloudFormation output.
https://app.<AppAddress>.nip.io
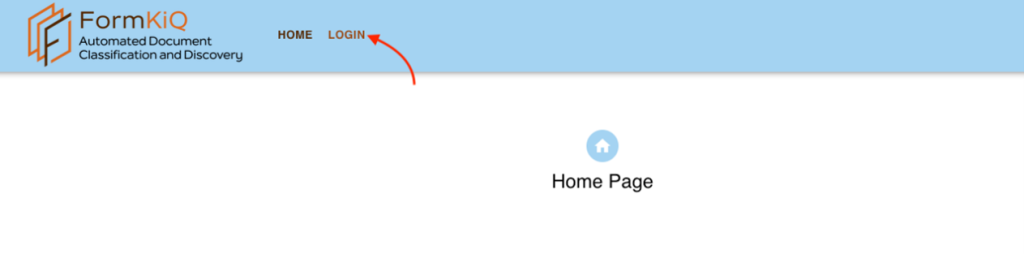
Visiting the URL should display the application homepage as shown below:
Technology Demonstration
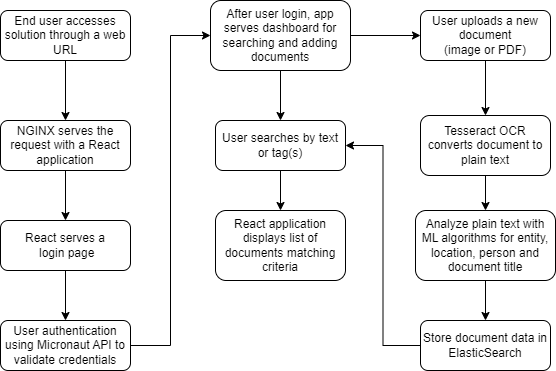
This section guides you through a demonstration of the Automated Document Classification and Discovery BoosterPack. Using this BoosterPack is worthwhile because it can automate the creation of document metadata/tags and improve the discovery and categorization of documents.
The demonstration will illustrate how to:
Upload a new document
Use Tesseract OCR to convert document to plain text
Analyze plain text with ML algorithms for entity, location, person, and document title
Store document data in Elasticsearch
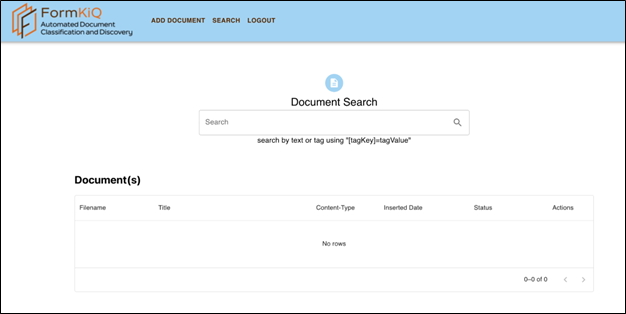
Conduct user searches for documents by text or tag(s)
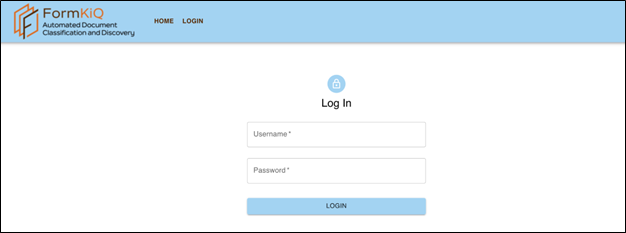
Login Page
The Automated Document Classification and Discovery application is accessible via a web browser using the secured URL: https://app.<AppAddress>.nip.io
Enter the username and password you configured when you installed the BoosterPack.
Click Login, then enter the username (WebUsername) and password (WebPassword) set in the CloudFormation parameter configuration during the BoosterPack deployment.
Document Search
Once logged in, the Document Search page allows you to search for documents using full text or tag(s).
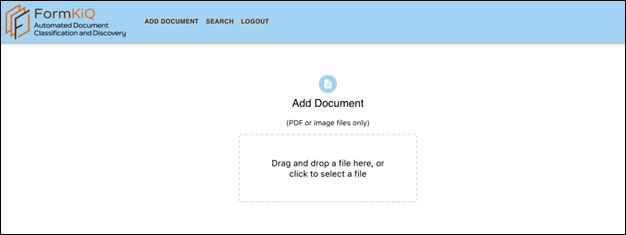
Add Document
The Add Document page allows you to upload one or more documents. Once uploaded, the documents will be converted to plain text via optical character recognition, and then machine learning algorithms will generate entity tag(s) and the document title.
Termination
Delete the instance in the DAIR Cloud to terminate the solution and release any resources it consumes. To do this, return to the CloudFormation stacks page and delete the stack corresponding to the BoosterPack. More information about deleting a CloudFormation stack can be found here.
Factors to Consider
Alternate Deployment Options
This solution is deployed on a single-node Elasticsearch instance. For higher performance and availability in larger solutions, you may need to create multiple instances in your DAIR Cloud and set up an Elasticsearch cluster. Managing an Elasticsearch cluster for small solutions like this Sample Solution may add unnecessary complexity and overhead.
The solution also uses a single Docker instance to manage the UI, Micronaut API, and Machine Learning (ML) API. The ML API can use a large number of server resources depending on the size of the documents being processed. For your use case, you may want to run a second instance of this solution and only run the ML API on the second instance. You will need to make minor modifications to the docker-compose-prod.yml to configure the API_ML server.
Technology Alternatives
The technologies and tools in this solution were selected from popular open-source technologies that integrate well together. These technologies can be replaced with other proprietary or open-source tools, depending on your platform, skillset, and support needs. For example:
Item
Proprietary
Open Source
Tesseract OCR
AWS Textract/Google Vision OCR
doctr
Docker
AWS Fargate
Kubernetes
Elasticsearch
Algolia
Typesense
Streaming solutions(Kafka alternatives)
Azure Event Hubs
RabbitMQ, Amazon MQ, Redis
Presentation Layer (React
n/a
Angular, Vue
Data Architecture
The sample solution stores files in the server’s filesystem and uses Elasticsearch for all metadata storage. This is an excellent example of understanding the concepts, but a production workload may be better served by using cloud storage (such as Amazon S3). While Elasticsearch is primarily suited for full-text search (along with Algolia and Typesense), other applications could be better served by using a database like PostgreSQL, which also provides more limited full-text functionality.
Access to the data is simplified, with only one access level provided. Role-or attribute-based access control would be recommended for scenarios where multiple users are expected to have different access levels.
Security
The Automated Document Classification and Discovery Sample Solution is designed for demonstration purposes and can be used as a basic framework to speed up the development stage of your solution. This solution is not intended to be used in a production environment; several security measures and improvements are required to make it suitable for a production environment. The following points describe considerations to make it more secure:
Password: We have set default passwords for several tools and applications in this solution, such as Elasticsearch and the UI. Always change default passwords using your own strong passwords.
Web Application Firewall (WAF): Using a WAF in front of the UI and API will prevent SQL injection, cross-site scripting (XSS), and cross-site request forgery (CSRF).
Scaling/Availability
The solution was built using a microservices infrastructure. Scaling a microservices architecture involves scaling individual services and their underlying infrastructure to meet increased demands.
Elasticsearch can be scaled by setting up an Elasticsearch cluster. Elasticsearch clusters are designed to handle large amounts of data and queries, and they can be scaled horizontally as needed by adding more nodes to the cluster. This allows for increased performance and reliability as the cluster grows.
APIs can be scaled by setting up an NGINX cluster. NGINX is designed to handle high-traffic loads and can be used to improve web application performance. By setting up a cluster of NGINX servers, you can distribute incoming requests across multiple servers, reducing the load on each server and improving overall performance.
API
This solution has a publicly accessible API endpoint; therefore, it is essential to ensure that all APIs require some kind of authentication. The solution uses JWTs to secure the APIs. JWTs provide a secure and standardized way to represent claims and exchange information between two parties.
Cost
One advantage of this solution is that all the integrated tools and technologies are open source, with no licensing costs. However, depending on the number and size of documents that will be processed and stored, larger servers may be required.
License
All code and configuration in this package are licensed under theApache 2.0 License.