The DAIR Program is longer accepting applications for cloud resources, but access to BoosterPacks and their resources remains available. BoosterPacks will be maintained and supported until January 17, 2025.
After January 17, 2025:
Screenshots should remain accurate, however where you are instructed to login to your DAIR account in AWS, you will be required to login to a personal AWS account.
Links to AWS CloudFormation scripts for the automated deployment of each sample application should remain intact and functional.
Links to GitHub repositories for downloading BoosterPack source code will remain valid as they are owned and sustained by the BoosterPack Builder (original creators of the open-source sample applications).
This Sample Solution, from the Time-Series AI Anomaly Detection BoosterPack, demonstrates how Chillwall AI used deep learning models and Autoencoders to solve the problem of anomaly detection.
The Time-Series AI Anomaly Detection BoosterPack demonstrates the use of advanced technologies to simplify a complex and costly big data solution that is often overlooked yet critical to business operations.
This material is informed by the solutions that we develop at Chillwall AI to bring the power of AI to everyday personal context predictions.
Problem Statement
In today’s ever-changing landscape of Big Data, anomaly detection plays a pivotal role in safeguarding business stability.
Anomaly Detection Matters
Do you use Big Data in your solution? Nearly every industry is reliant on data. Left undetected, data anomalies can be highly disruptive affecting product safety, cyber threats, financial losses and process optimizations.
Business as Usual Challenge
Within our vast operational data representing our normal business lurks data anomalies: unexpected deviations, subtle shifts or unusual occurrences. Here lies the potential to disrupt your everyday business.
Complex Solution – Often Overlooked by SME’s
Organizations use top level solutions like security detection software, but early detection is best solved at the system or code level. Canadian SME’s lack the expertise and development time to build complex anomaly detection algorithms (especially where machine learning and data science is not a core competency). This limits speed to market and rapid prototyping of innovative solutions. Purpose-built anomaly detection requires specialized data scientists, network engineers and software developers requiring 6 months or more to build.
Advanced Deep Learning Solution – At your Fingertips
This Sample Solution utilizes Artificial Neural Networks (Autoencoders) to identify abnormal patterns in time-series operational data. An autoencoder is employed for unsupervised learning to compress input data and reconstruct it with minimal error. In this context, the challenge lies in training the autoencoder on a representative set of normal data, capturing its underlying structure. Once trained, the autoencoder is tasked with reconstructing new data instances, with anomalies identified by deviations in the reconstruction error from the norm. We include an ECG sample dataset as a sample reference for data structure and model run.
This BoosterPack offers significant value to an SME:
Turn-key solution with limited technical knowledge required.
Virtual cloud environment set up for you.
Allows upload of raw unsupervised data sets.
Automated AI model trains your data.
Low-cost fast solution. Runs within your DAIR budget.
Time-Series AI Anomaly Detection in the DAIR Cloud – Sample Solution
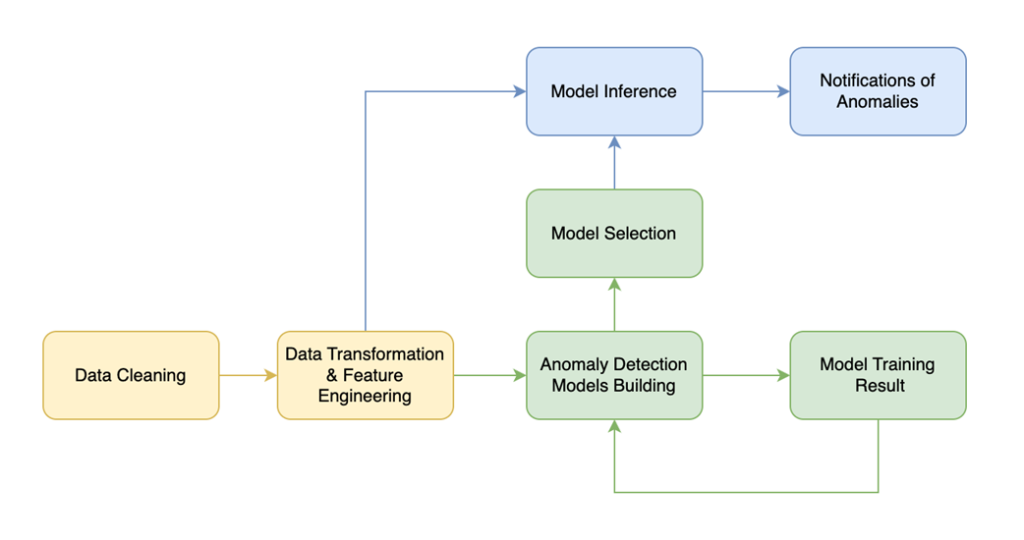
Sample Solution Overview Diagram
The diagram below illustrates the structure of the Sample Solution.
Component Descriptions
Significant components used in the Sample Solution are summarized in the table below:
Component
Description
Data Cleaning
Detecting and correcting or removing private, corrupt or inaccurate records from dataset.
Data Transformation &Feature Engineering
Transform the values of a dataset into a common scale.
Anomaly Detection Building
Build deep learning model to detect anomalies with training data.
Model Training Result
Calculate accuracy of anomaly detection model.
Model Selection
Select models with best accuracy.
Model Inference
Elasticsearch is a distributed, open-source Run the final selected model.
Notification of Anomalies
Detect and notify.
Technology Demonstration
This section guides you through the configuration & deployment of the application powered by artificial neural networks (ANN’s).
How to Deploy and Configure
If you’re a DAIR account holder, you can deploy the Sample Solution by navigating to the Time-Series AI Anomaly Detection BoosterPackand following instructions on the page for deploying a new instance. The solution will auto-configure your virtual environment.
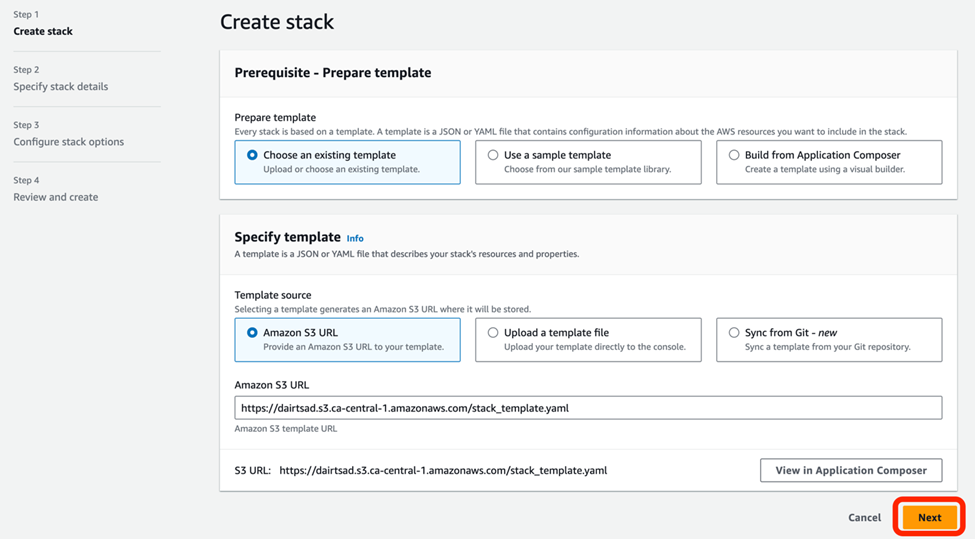
1. Click Deploy, then sign into your DAIR account to open the Anomaly Detection BoosterPack stack URL. Click Next on Create Stack page
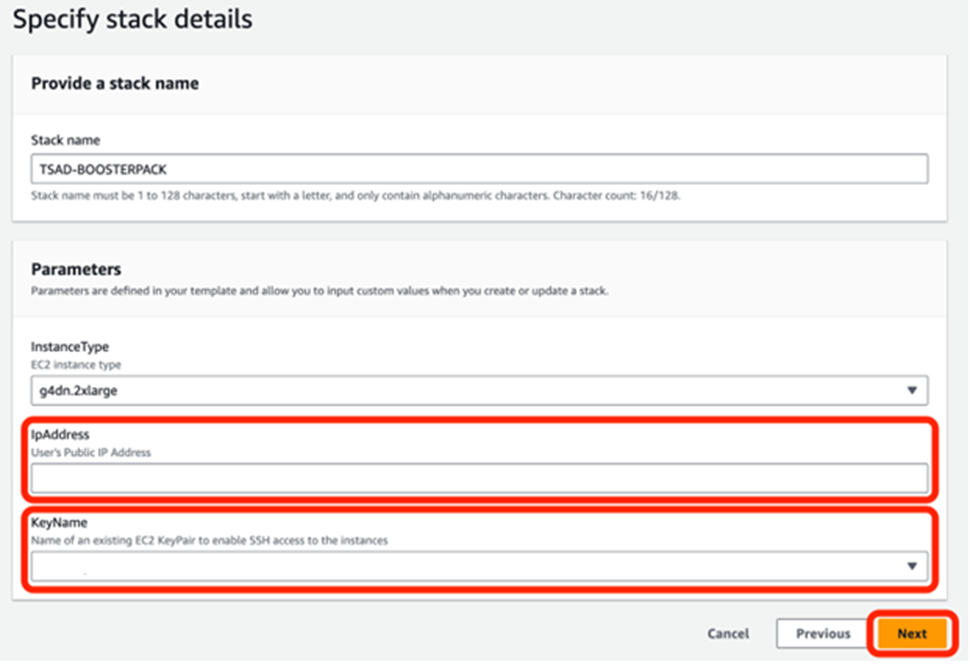
2. In Specify stackdetails page, please configure as shown below:
From IpAddress box, enter your company public IP address
From the KeyName box, select your existing EC2 KeyPair for SSH access to your instance
Click Next
3. In Configure stack optionspage, select Next.
4. In Review and create page, select Submit.
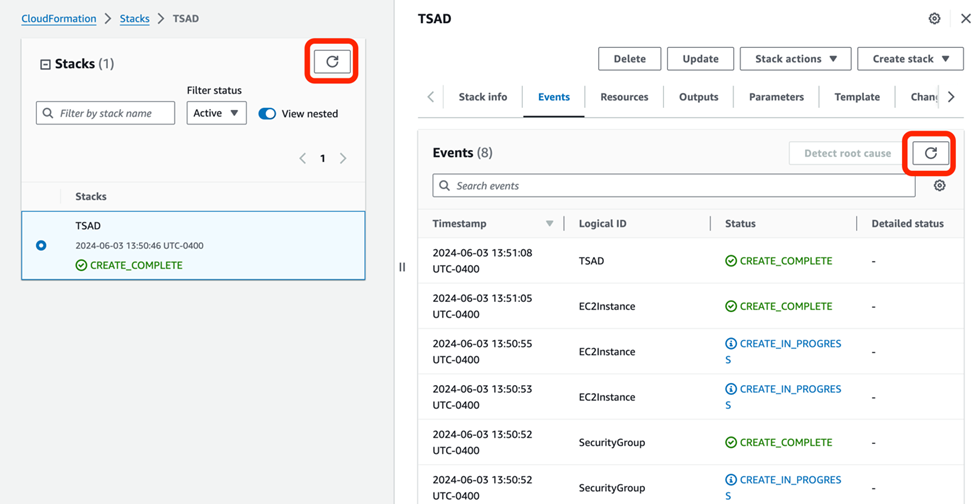
5. The stack will be created and deployed successfully as shown below, you can click refresh button to check updated stack status.
Configuration and Application Launch
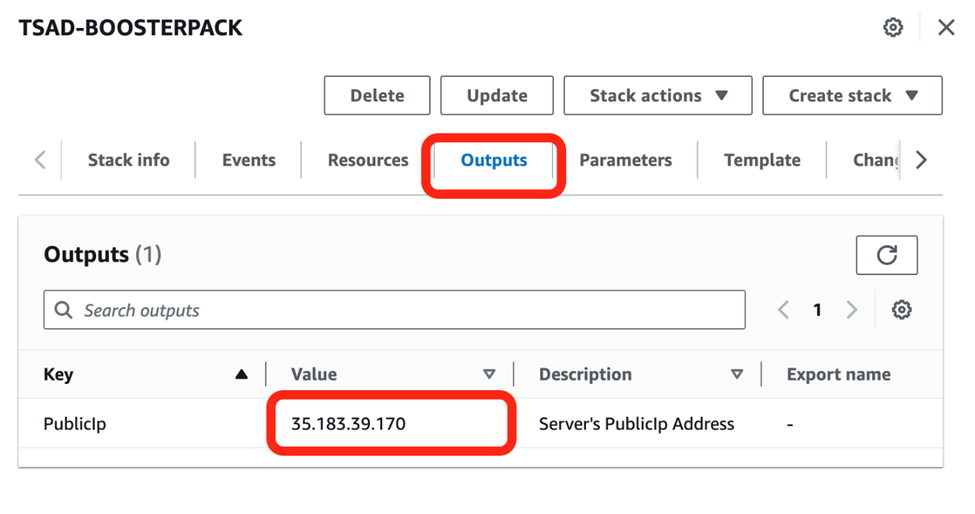
1. Once your stack is created successfully, click the Outputs tab to view your instance IP Address located under Value. Use this IP Address to access your GPU instance via SSH command.
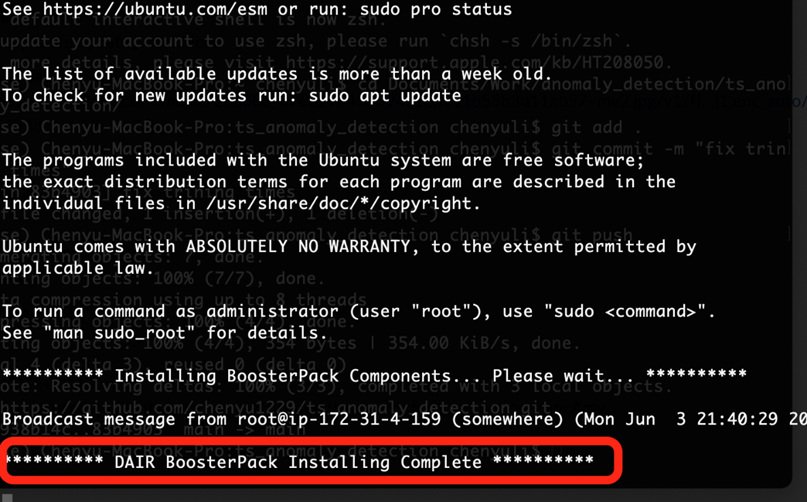
2. After gaining access to your GPU instance, wait until the following DAIR BoosterPack Installing Complete message is shown in your console. Press Enter to advance to next step.
A sample code and dataset will preload with high model accuracy and the ability to change parameters for your model familiarity. See Technology Demonstration section and Data Architecture section below for more guidance on parameter settings and uploading your own dataset.
3. Run the following 3 commands, then your virtual environment is activated!
This section guides you through a demonstration of the Time-Series AI Anomaly Detection BoosterPackusing Deep Learning Artificial Neural Networks (Autoencoders) is compelling because it identifies operational anomalies at the lowest base level.
The demonstration will illustrate a sample use case as guidance for your operational modeling.
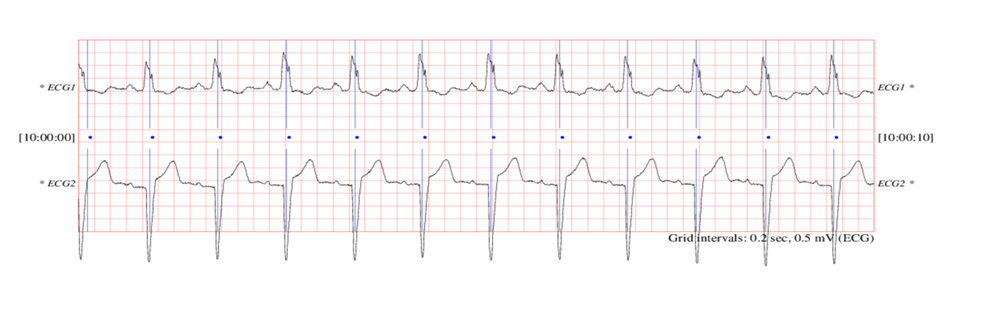
Electrocardiogram ECG Dataset Example
Understanding Your Dataset
The original dataset is a 20-hour long ECG downloaded from Physionet. The name is BIDMC Congestive Heart Failure Database (chfdb) and it is record “chf07”. In this dataset, we are using 5000 Electrocardiograms. Columns 0-139 contain the ECG time-series data point for a particular patient, and each example has been labeled either abnormal rhythm or normal rhythm.
In this anomaly detection Sample Solution, we will demonstrate the transformative capabilities of Autoencoder deep learning models. Through sophisticated encoding and decoding mechanisms, our system learns intricate patterns from ECG time series data, enabling it to finding the irregular heart rates, heartbeats, and rhythms. See ECG sample dataset as a sample reference.
1.Model Training: To train the model, you need to run following two commands:
cd anomaly_detection/src/
python3 train_model.py
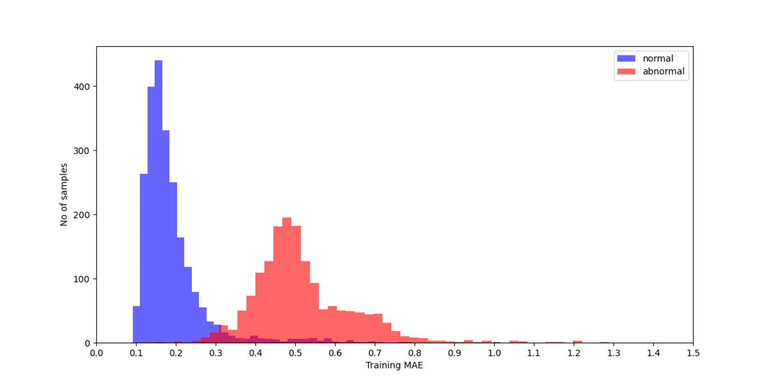
2.Setting a Threshold: After we train the Autoencoder model using the training dataset, we calculate the reconstruction loss for every ECG record and draw a histogram graph. The graph will be saved at /reports/ training_MAE_loss.jpg.
Although some abnormal rhythm seems to fool the Autoencoder, their data clearly exhibits a discernible feature that distinguishes it from normal data. We would set a threshold that distinguishes between normal and abnormal behavior patterns in the data, then we can control the rate of false positives, while also capturing most anomalous data points. The default value is 0.3 for ECG dataset, you need to find new threshold value if you use your own dataset and update this value in scripts.
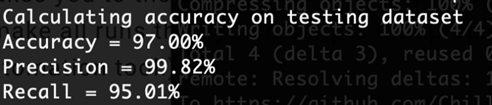
3.Model Accuracy Test: After threshold setting, we will test our model accuracy using the test dataset, you will see the report of accuracy, precision and recall as following below.
Model Accuracy Report
Model Accuracy Evaluation
Description
Accuracy
Accuracy shows how a classification ML model is correct overall.
Precision
Precision is the ratio between the True Positives and all the Positives. For our problem statement, that would be the measure of patients that we correctly identify as having a heart disease out of all the patients actually having it.
Recall
Recall is the measure of our model correctly identifying True Positives. Thus, for all the patients who actually have heart disease, recall tells us how many we correctly identified as having a heart disease.
4.Run Anomaly Model Inference: After the model is built and selected as final model, you can run following command for model inference:
python3 predict_model.py
Result
Your result will be generated and saved at /result/predicting.csv
Termination
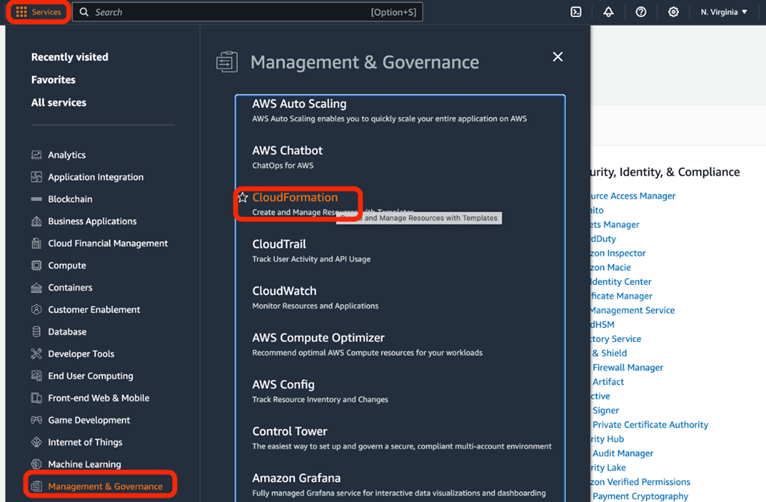
1. After finishing the sample demonstration, navigate to Services > Management & Governance > CloudFormation
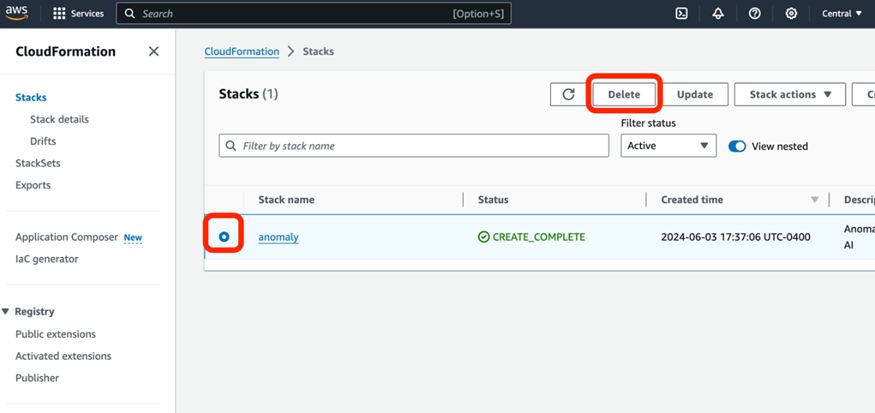
2. Select the check box of your stack, click Delete. Then, the stack, EC2 instance, and security group will be deleted automatically from your account.
Factors to Consider
Alternate Deployment Options
The Anomaly Detection sample solution BoosterPack utilizes a cost-effective GPU g4dn.2xlarge instance. This instance meets the needs of most use case scenarios.
Technology Alternatives
Top Reasons for Choosing Artificial Neural Networks (Autoencoders)
One of the key technology decisions in this solution was Autoencoders which are well suited to the Anomaly Detection task.
Autoencoders capture non-linear relationships and complex patterns in data, making them suitable for detecting anomalies in high-dimensional and complex datasets.
Autoencoders capture both global and local patterns in the data. This flexibility allows them to detect anomalies at various scales, from subtle local deviations to global anomalies affecting the entire dataset.
Autoencoders can learn from unbalanced or unlabeled data, making them particularly valuable when labelled anomaly data is scarce or unavailable.
Alternative Solutions
If you have a small dataset, the anomaly is not complex to identify or depends heavily on the interpretability of the model, then these are alternative solutions:
Use statistical modelling methods like Gaussian mixture models; these methods rely on modelling the statistical properties of the data and identifying data points that deviate from expected patterns as anomalies.
Use traditional machine learning algorithms such as Support Vector Machines (SVMs) or Random Forests to classify the data, and then detect anomalies by identifying misclassified data points.
Use rule-based methods like rule engines based on domain expert knowledge, which can detect anomalies based on specific domain experience rules.
Data Architecture
Sample Solution Data Format Guidelines
Data Upload – Sample Dataset Preloaded
ECG dataset saved in Sample Solution Github repo automatically downloads after stack/instance is created. This allows first time users the opportunity to learn and test the model.
Data Upload – New Datasets
Users can send their own datasets to the instance using the SCP command. For a step-by-step guide, please refer to Transferring Files between your laptop and Amazon instance. It is important to use the same file name as the current file to replace the old datasets.
Input Data Format
Sample Dataset
ECG dataset is in CSV format, and it has 140 columns which represents the ECG readings and a labels column which has been encoded to 0 or 1 showing whether the ECG is abnormal or normal. This is a sample of the data format as guide for new datasets.
New Dataset
Using you own dataset; these are the format requirements:
Dataset’s format is CSV without header and index, but user can modify the function pd.read_csv in train_model.py and predict_model.py to accept index and column names, if required. Please refer to Pandas Read for more details.
Only numeric data points are accepted. If you have other data in the dataset, please convert it into a numeric data type. Please refer to Label Encoders for more details.
Each row represents a period of time series data, and the last column is the label column.
No timestamp column is required in this data format.
Input Data Quality Check
The quality of the prediction is linked to the quality of the training dataset, so quality of dataset is one of the most important factors in Machine Learning. When you select your own dataset, try to avoid the following:
Inaccurate dataset
Inaccurate data can significantly reduce the performance of machine learning models. Be sure to understand your data to identify bad data at the pre-processing stage.
Unbalanced dataset
Avoid imbalanced datasets where anomalies are rare compared to normal instances. Imbalanced data can bias the model towards normal behavior, leading to poor detection performance. (See Imbalanced Data in Tutorial section of Flight Plan for more details)
Dataset lack of documentation
Lack of proper documentation can lead to misinterpretation of the data, incorrect analysis.
Output Data Format
Output dataset format is CSV with header and index, the first column is index, and second column predicts the result which has been encoded to 0 or 1 showing whether the ECG is abnormal (0) or normal (1).
Security
The Autoencoder-based anomaly detection solution is designed as a basic framework to speed up the development stage of your solution. The following security concerns and mitigating controls should be considered:
Concern
Mitigation
Data transmitted to and from EC2 instances could be intercepted, exposing sensitive information.
Use SSH for secured data transmission.
Unauthorized access to EC2 instances could lead to data breaches or tampering with the system.
Implement AWS Identity and Access Management (IAM) to control access to EC2 instances, ensuring only authorized users and services have access. Utilize security groups to restrict network traffic.
AWS Login Passwords
Always change default passwords using your own strong passwords.
Networking
Not applicable to this BoosterPack.
Scaling
Scaling in Anomaly Detection refers to the ability of the technology to handle increasing volumes of data and maintain its performance as the size of the dataset grows. Utilizing parallel processing techniques, such as multi-threading or multi-processing, can help improve the scalability of anomaly detection systems by leveraging multiple computing resources simultaneously. We utilize Tensorflow and CUDA cores for multiprocessing when performing operations for model training. CUDA is a parallel computing platform and application programming interface (API) model, which allows TensorFlow to efficiently utilize GPU resources for parallel computation. If multi-threading or multi-processing are needed for data pre-processing, please refer to Thread-based parallelism and Process-based parallelism for more details.
Availability
Our project deploys in the DAIR AWS EC2 instance, and EC2 instances are deployed across multiple physical servers within an Availability Zone (AZ), so if one server fails, the instance can be quickly migrated to another healthy server. Regularly backup data to mitigate potential data loss.
User Interface (UI)
Not applicable to this BoosterPack.
API
Not applicable to this BoosterPack.
Cost
This BoosterPack is a low-cost solution within your DAIR account. This BoosterPack is designed to be run many times per month within your DAIR account budget. This application deploys on On-Demand Linux g4dn.2xlarge Instance, the price is USD 0.835/hour.
License
All code written by Chillwall AI are licensed under the MIT license.
The following terminology, as defined below, is used throughout this document.
Term
Description
API
Application Programming Interface
DAIR
Digital Accelerator for Innovation and Research. Where used in this document without a version qualifier DAIR should be understood to mean DAIR BoosterPack Pilot environment (a hybrid cloud comprised of public and private cloud vs. the legacy DAIR private cloud service). A hybrid cloud environment
Deep Learning
Machine learning with artificial neural networks
ECG
Electrocardiogram
GPU
Graphics Processing Unit
Hyper-parameter
A parameter set prior to model training, as opposed to those derived during training
Instance
When you run virtual machines in the cloud environment, they are known as instances.
LSTM
Long Short-Term Memory (Network)
Machine Learning
Framework of building models without explicit programming.
Overfitting
The production of an analysis that corresponds too closely or exactly to a particular set of data and may therefore fail to fit to additional data or predict future observation’s reliability.
Time-Series
A sequence of data taken at successive equal time-intervals.