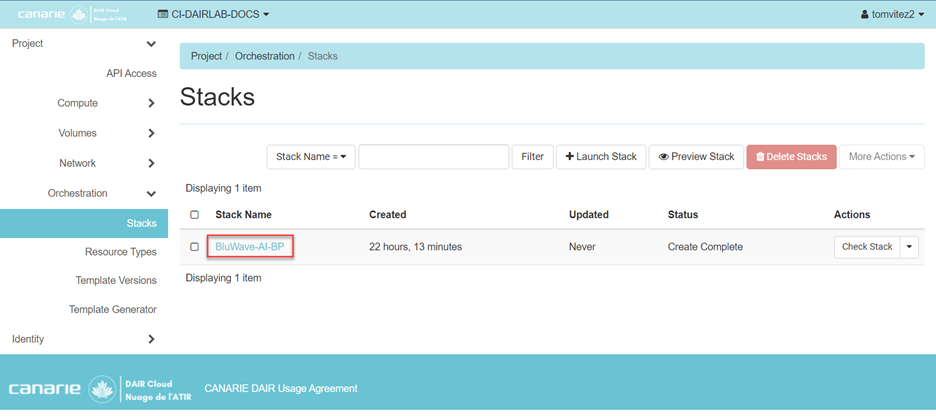
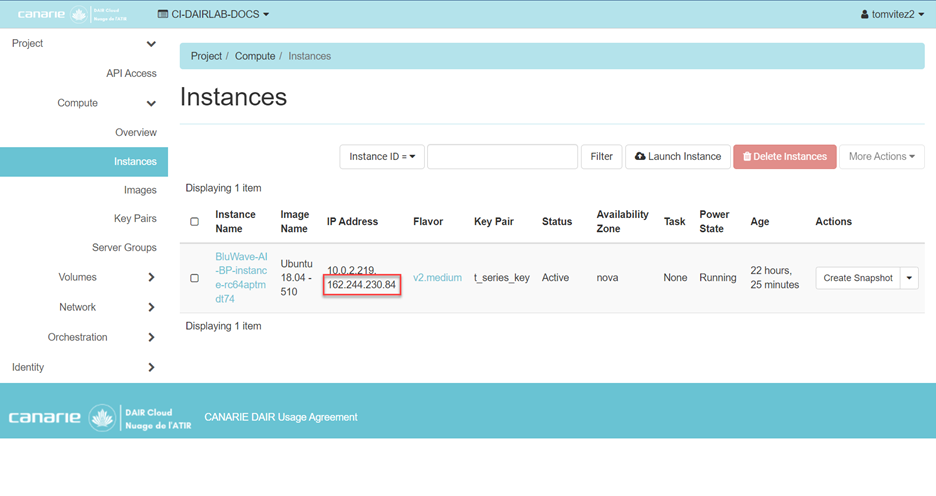
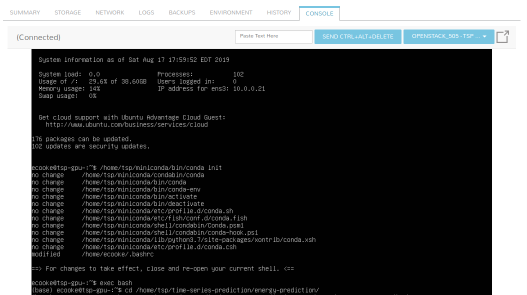
Technology Considerations
Deployment Options
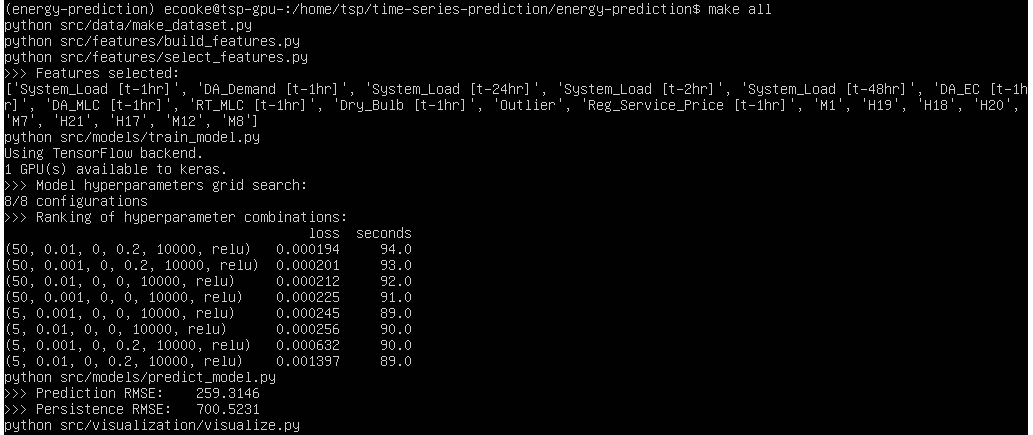
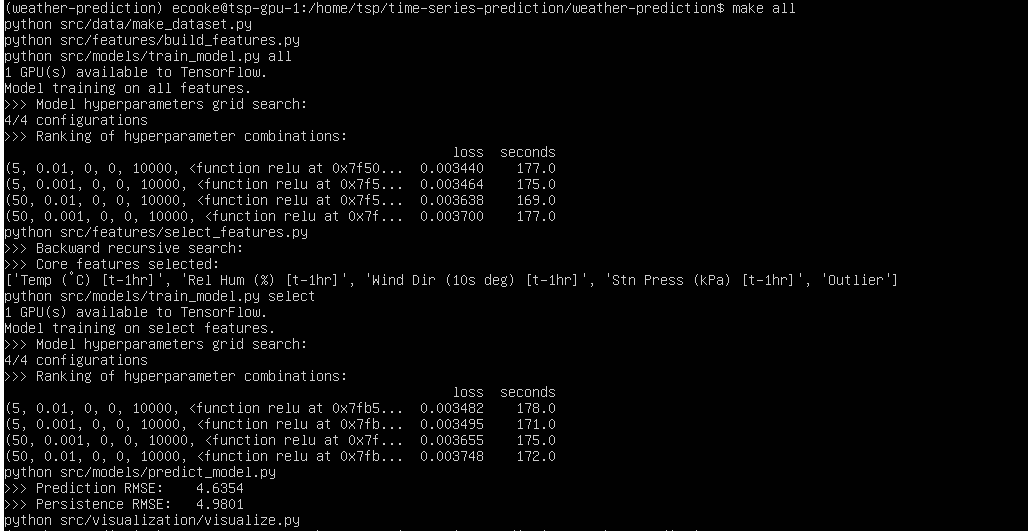
To improve predictor performance, you could increase the space over which the hyper-parameter grid search is done. This requires adding more values to the values in the dictionary in src/models/train_model.py, as in the Model A snippet shown below:
105 all_params = {'num_hidden': [75, 35],
106 'learn_rate': [0.001],
107 'lambda': [0, 0.01],
108 'dropout': [0, 0.2],
109 'num_epochs': [10000],
110 'activation': ['relu']}
Broadening the hyper-parameter search is done at the cost of time, since it requires exponentially more models to be trained and evaluated.
The Python scripts that constitute the Sample Solution are only supported on Linux systems.
Technology Alternatives
One of the key technology decisions in this solution was to use an ANN as the machine learning model, and we built a multi-layer Perceptron (MLP) with Back-propagation. This was done for the sake of simplicity, as a perceptron is the most basic form of an ANN. However, a strong alternative is a recurrent neural network (RNN), as it can exhibit temporal dynamic behaviour relevant to time-series. Long short-term memory (LSTM) networks are very powerful RNNs and should be explored to achieve better performance for more complex problems.
Artificial neural networks need not be used. With time-series prediction you almost always face a regression problem, where your prediction is a real number. Other models such as linear regression or polynomial regression can be very effective. You may consider these methods if you have a relatively small data-set, or depend heavily on the interpretability of the model, since ANNs are inferior in these areas.
In terms of software development, we chose to use the Keras and TensorFlow libraries in Python to implement the model. This decision was based on the popularity of Python and these two libraries, but also because the Python + Keras is a great combination for beginners. Alternative machine learning libraries in Python are Theano, PyTorch, and scikit-learn. Alternatives in C++ are Microsoft CNTK and Caffe, and in C, Torch. These all generally yield improvements in speed over Python implementations.
Data Architecture Considerations
Not applicable to this BoosterPack.
Security Considerations
Not applicable to this BoosterPack.
Networking Considerations
Not applicable to this BoosterPack.
Scaling Considerations
One of the strengths of Deep Learning is that great improvements in model performance can be achieved with larger amounts of training data. Besides needing to tune model hyper-parameters, the reference solution will scale to such data-sets. Of course, this performance increase comes at a cost. In this case, the cost is not only that of gathering more data, but demand for computing power and time.
To manage computational demands, you might consider using multiple GPUs. The reference solution makes use of a single GPU, but Keras and TensorFlow can harness multiple. As your data-set size increases, or your neural network grows in number of nodes, multiple GPUs will help mitigate training time because of their efficiency with matrix multiplication.
Availability Considerations
Not applicable to this BoosterPack.
User Interface Considerations
Not applicable to this BoosterPack.
API Considerations
Not applicable to this BoosterPack.
Cost Considerations
A major financial cost of training artificial neural networks is obtaining sufficient computing power. As your data-set and/or network grows, training becomes much more computationally expensive. You must consider whether to do your computation in the cloud or on-premises.
Another consideration is the cost of getting the data needed to train your ANN. Nowadays, the power of machine learning models comes primarily from the data with which they are trained, not the details of the implementation. In many cases the cost of obtaining this data may be the bottleneck in developing intelligent models.
License Considerations
All code written by BluWave-ai is available under the MIT license.
The data for Model A is obtained from ISO New England, and available according to the terms posted on their website, https://www.iso-ne.com. The data for Model B is obtained from the Government of Canada.
SOURCE CODE
Source code for the Sample Solution can be found in the BluWave-ai Github repository.
GLOSSARY
The following terminology, as defined below, may be used throughout this document and the BoosterPack.
| Term |
Description |
| ANN |
Artificial Neural Network. |
| Back-propagation |
Technique used to adjust the weights within a neural network. |
| DAIR |
Digital Accelerator for Innovation and Research. Where used in this document without a version qualifier DAIR should be understood to mean DAIR BoosterPack Pilot environment (a hybrid cloud comprised of public and private cloud vs. the legacy DAIR private cloud service). A hybrid cloud environment. |
| Deep Learning |
Machine learning with artificial neural networks. |
| GPU |
Graphics Processing Unit. |
| Hyper-parameter |
A parameter set prior to model training, as opposed to those derived during training. |
| Load |
Electrical component that consumes power. |
| LSTM |
Long Short-Term Memory (Network). |
| Machine Learning |
Framework of building models without explicit programming. |
| MLP |
Multi-Layer Perceptron. |
| Perceptron |
A single-layer artificial neural network. |
| Regression Model |
Model that outputs a real-number value. |
| RNN |
Recurrent Neural Network. |
| Supervised Learning |
Machine learning with labelled training data. |
| Target |
The quantity that you are interested in predicting. |
| Time-Series |
A sequence of data taken at successive equal time-intervals. |