The DAIR Program is longer accepting applications for cloud resources, but access to BoosterPacks and their resources remains available. BoosterPacks will be maintained and supported until January 17, 2025.
After January 17, 2025:
Screenshots should remain accurate, however where you are instructed to login to your DAIR account in AWS, you will be required to login to a personal AWS account.
Links to AWS CloudFormation scripts for the automated deployment of each sample application should remain intact and functional.
Links to GitHub repositories for downloading BoosterPack source code will remain valid as they are owned and sustained by the BoosterPack Builder (original creators of the open-source sample applications).
Sample Solution: Apption Data Assessment Tool
If you haven’t already, please review the Apption DAIR BoosterPack Flight Plan, Apption Data Assessment Tool, before implementing the Sample Solution below.
Introduction
The Apption Data Assessment Tool (A-DAT) is an open source project that provides a solution for:
Bootstrapping data science projects and recognizing over 30 data types
Uploading CSV files to any cloud SQL Server database (or local)
Generating an optimized data schema
Summarizing data fields and providing data quality metrics.
For these tasks, users would traditionally need to invest in expensive solutions built with numerous functions where data transformation has a narrow focus. This solution analyzes the data file in detail and proposes a schema accompanied with informative charts and graphs for each field in the file. The users can customize and control the final database table schema. Finally, the users can upload the data from the file into a database in the cloud.
While many ETL tools already address this issue, they can require significant effort to create packages – even for simple files – and end up being a bottleneck in any data exploration or science project.
This solution provides a minimal workflow, without any data transformations, to load any unstructured file to the cloud in few simple steps and with zero development effort.
Sample Solution
Solution Overview
Key Features
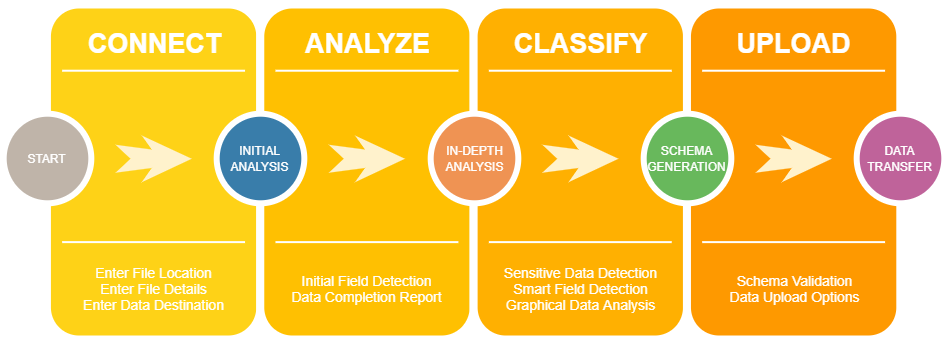
The solution can be split into four main sections:
Connect: The first interaction with the tool allows the user to input settings that the application uses to perform its analysis. These include the source data filename, file format details, and database connection strings.
Analyze: The initial analysis phase performs a first pass over the data, getting a high-level view of the data, and displays results to the user. Primary keys, basic types, data completion, and other statistics are determined at this phase.
Classification: The classification step does an in-depth analysis of each field and assigns it a data type. The user can then perform the simple task of verifying which fields will be added to the schema. Sensitive data along with graphs displaying the spread of data within each field are also displayed for the user to make decisions on whether they need to override the application’s suggested data type.
Upload: This final step allows the user to view the schema to be used in creating the database table. If the user is satisfied with the final schema, the data can then be transferred from the flat file into the database.
Fig. 1 – Sample Solution
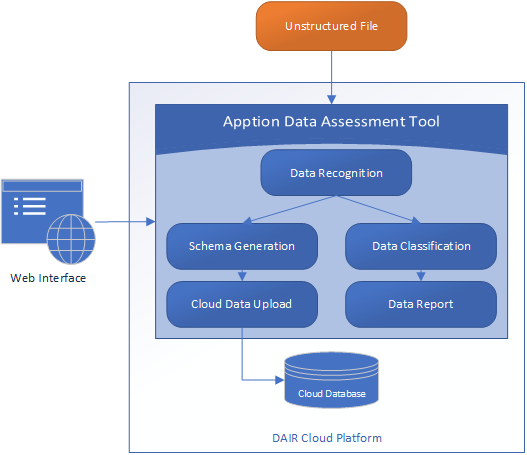
System Architecture
Component Descriptions
Component
Summary
DAIR Cloud Platform
The DAIR Cloud Platform provides a web-based user interface for participants to access DAIR resources.
Data Recognition
The data recognition component focuses on analyzing the file column by column and assigning appropriate metadata to each column. This component will recognize the major SQL types such as varchar, int, float.
Sensitive Data Detection
Sensitive data detection will be used to flag any potentially sensitive data in the files such as names, addresses, etc.
Web and Electron Interface
The solution can be executed either inside the Electron framework as a desktop application or executed on the cloud using a standard web portal.
Cloud Data Upload
This component will use optimized data transfer interfaces to upload the data from the unstructured file into a cloud database.
Data Report
This report will show the result of the analysis and the results of the sensitive data analysis.
Apption Data Assessment Tool Deployment
The Apption Data Assessment Tool (A-DAT) is available in the public Docker Hub in the Apption Repository and is used to deploy the BoosterPack sample solution to AWS using CloudFormation. The CloudFormation script will deploy both Apption Data Assessment Tool (A-DAT) tool and a SQL Server instance as Docker container applications.
Deploying Apption Data Assessment Tool in DAIR Cloud
While the application does a lot of heavy lifting in the back end, one of our goals was to make the front end as simple and intuitive as possible. There is no configuration required once the application is up and running; users simply need to know the location of their data files and the connection string of their database.
The following details will be used during the configuration/deployment of the Apption Data Assessment Tool containerized application.
A DAIR account is required for the deployment of the Apption Data Assessment Tool BoosterPack within its cloud space. The application is deployed to an AWS Linux instance.
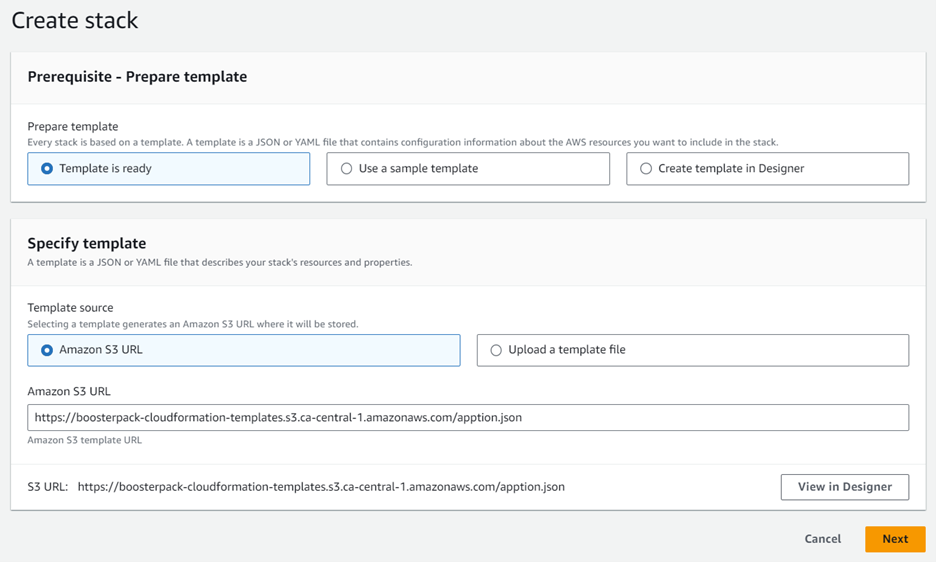
From the DAIR BoosterPack catalogue page, go to the Apption Data Assessment Tool section and click DEPLOY to launch the BoosterPack using AWS CloudFormation stack.
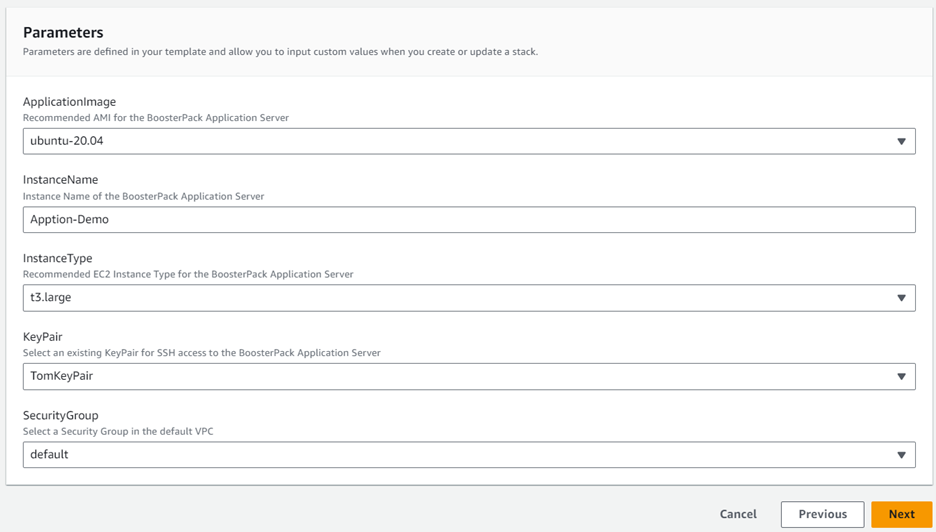
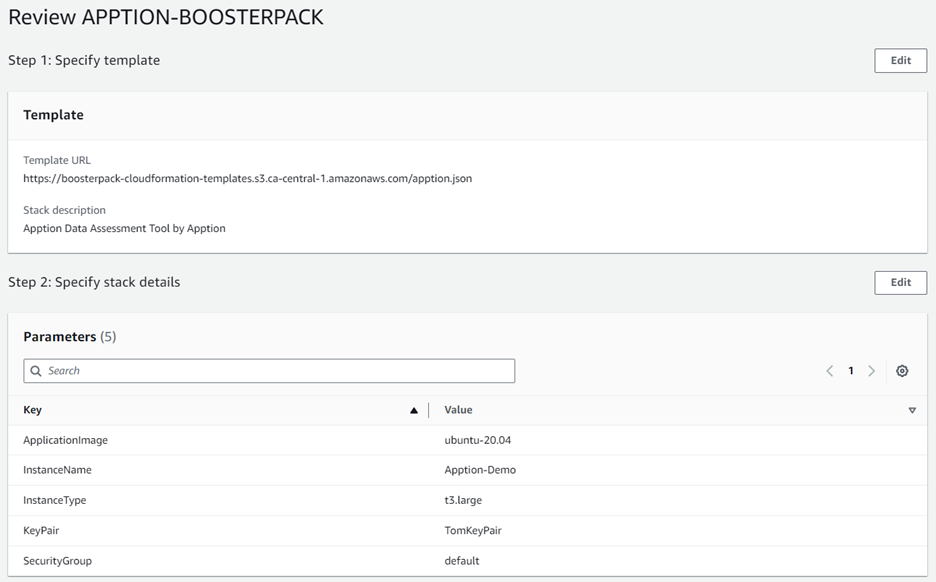
Click Next to go to CloudFormation step 2 and fill out the parameter configuration form. In the InstanceName field, type in a unique instance name for your application server and then complete the rest of the form using the drop-down options. Please note that parameters (such as “ApplicationImage” and “InstanceType”) are pre-configured and cannot be modified.
Once you are done, click Next to go to CloudFormation step 3. This section is for configuring additional/advanced options which are not required in our use case. Simply click “Next” at the bottom of the page to skip step 3 and get to the final CloudFormation step 4.
The final section allows you to review existing BoosterPack configurations and provides options for making configuration changes, using the Edit button, if needed. Once satisfied with the existing configuration, click Submit at the bottom of the page to deploy the BoosterPack.
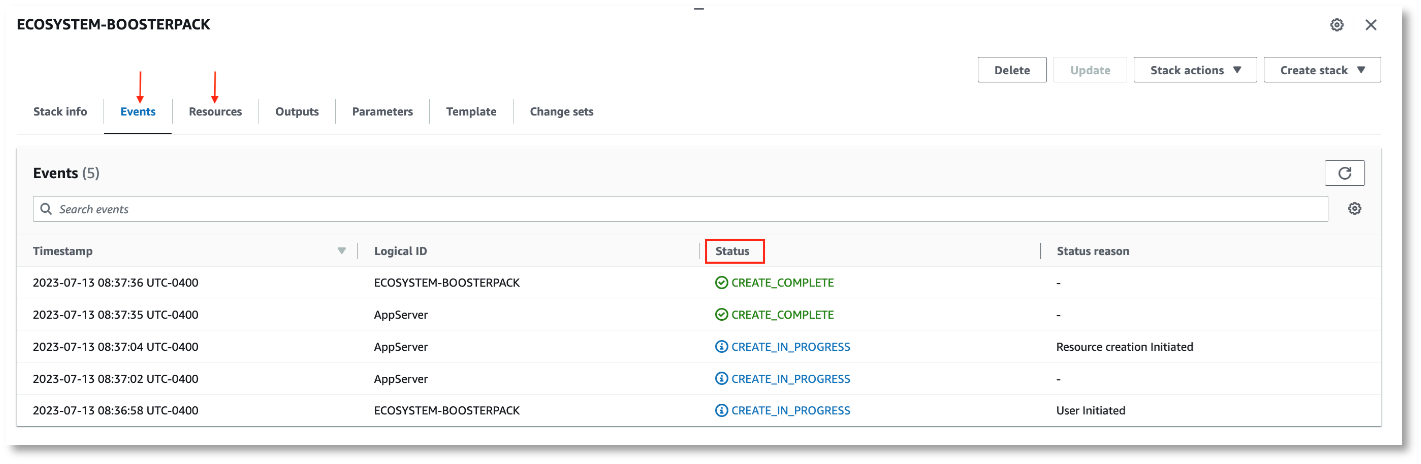
The BoosterPack deployment will start by creating a new instance and the deployment automation will follow. However, you can only monitor the AWS instance status through the Events and Resources tab of the CloudFormation page. You will need to log in to the application server to confirm the deployment automation status.
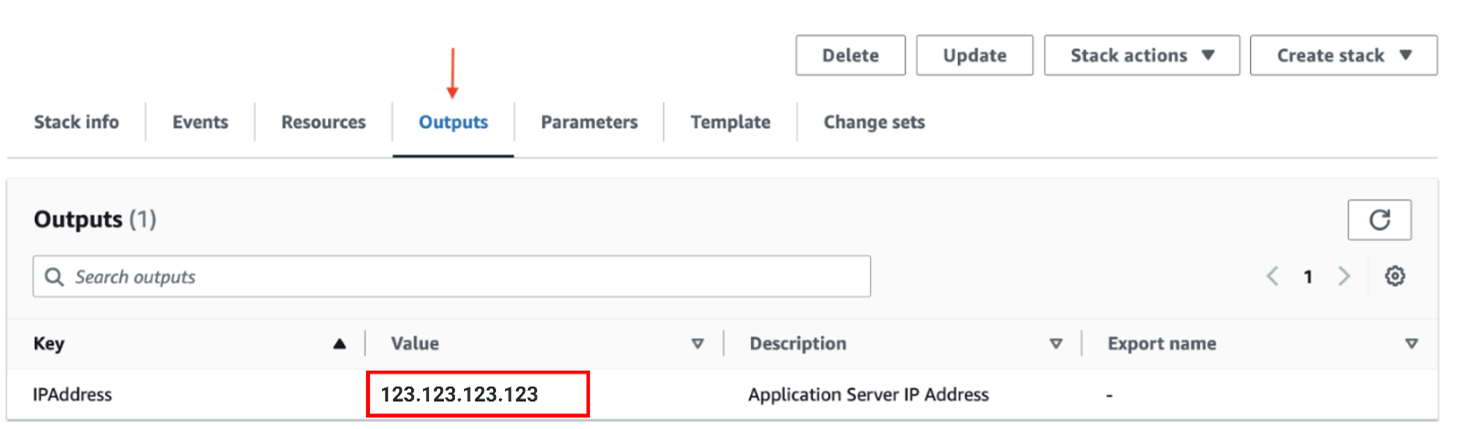
Note: Record the IP address value found under the “Outputs” tab of the BoosterPack CloudFormation page. This is the external IP of the instance that is being created. You will need this IP address to access the web interfaces of the sample application.
Using the SQL Server database is optional. If you want to import data from the web application to a SQL Server database, you will first need to test the connection to the installed SQL Server and create a database using SQL Server Management Studio (SSMS). SSMS can be downloaded here.
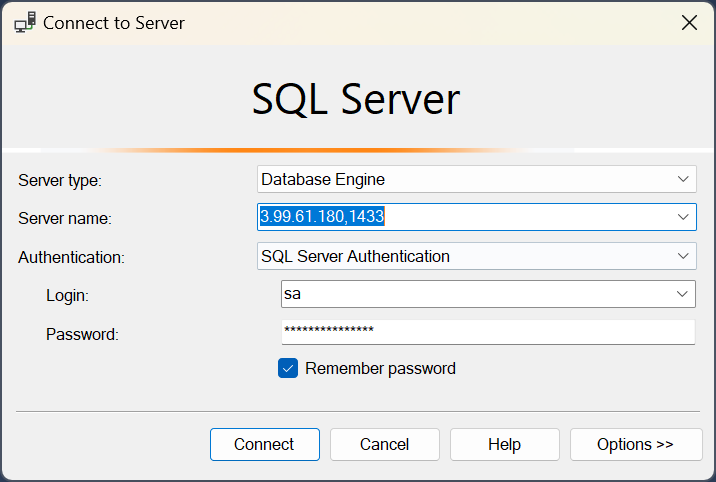
The Server name has to follow the convention <IP>,<port> using the public IP and default port (e.g. 3.99.61.180,1433).
Note: Microsoft SQL Server Management Studio uses a comma “,” (not a colon) to separate the IP and port number for the Server name input field shown below.
Connection Parameters for SQL Server Management Studio
Once connected to the database server, create a test database for the app to upload data to. This can be done by right-clicking Databases and selecting New Database.
Follow the instructions in the wizard to complete the database setup.
To use the A-DAT web application, open a new browser window pointing to the public IP and default port of 8000 (e.g. http://3.99.61.180:8000) for the Docker image.
Important Note: To access the A-DAT web application, you must provision your machine’s external IP in the default AWS Security Group; otherwise, the connection will be refused.
If you plan to use the database in SQL Server, the target DB connection string format is:
Server IP value must be the internal IP (not public),
Initial Catalog is the name of the database you created with SSMS,
Uid and Pwd are the default values (sa and Welcome2Adat!) created automatically during deployment of the BoosterPack.
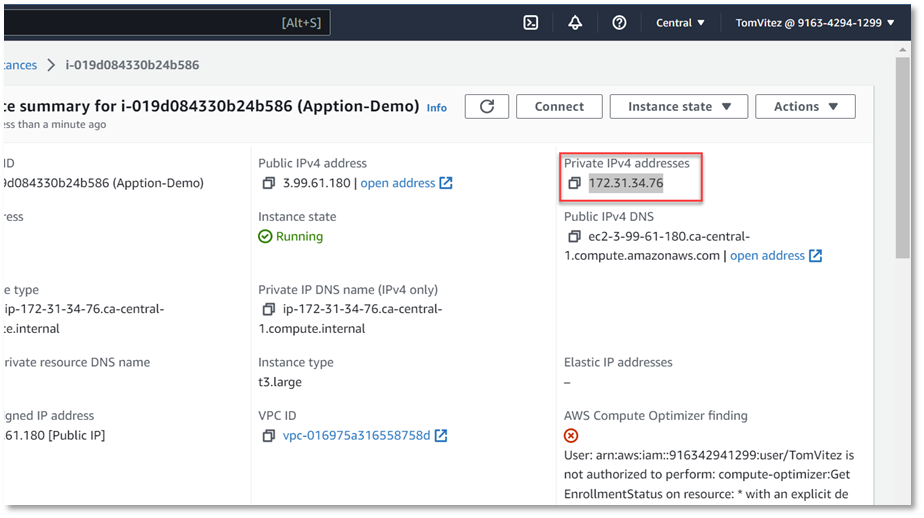
To determine the private IP address, look at the EC2 Instance summary page in AWS.
Working with Source Code
The following section describes how to set up your development environment should you chose to experiment with the application code, rebuild it, and deploy the new version to see the effects of your changes. To work with the source code, it must be pulled from the CANARIE repository (Gogs) and launched in Visual Studio 2019 (interactive development environment or IDE). From the IDE, the following Run options are available:
Local Web App execution
Standalone Electron App
To run the materialize web-app (see the screen shot below), press the green play button to launch.
Prerequisites 1-3 must be in place to allow the Apption Data Assessment Tool to successfully build in Visual Studio.
Prerequisites 4-5 are needed to transfer the binaries from the Apption Data Assessment Tool build into a Docker image for distribution.
Creation of a Docker Image
This step assumes that the Apption Data Assessment Tool source files have already been cloned locally and the solution can be opened and built successfully within Visual Studio. Prerequisites 1-4 above must be satisfied.
The .Net core environment and Blazor extension allows a Windows executable to run on a Linux host. This allows a Docker image to be built on the default Linux OS.
We will be creating a Docker image by pulling a Microsoft-supplied Docker image that already has .Net core and Blazor pre-installed and then adding extra libraries and executables on top. The final result will be a Docker image which can be pulled and run by any Docker client.
Publishing or Building the Apption Data Assessment Tool Locally
Right-click on the ‘WebAppMaterialize.Server’ project in Solution Explorer and click on ‘Open Folder in File Explorer’.
This will open a FileExplorer. Drill down the ‘bin’, ‘Debug’ and ‘netcoreapp2.1’ directories.
You will see a set of .dll, .json, .config files and a file called ‘Dockerfile’ (which has no extension).
Click in the space just after the full directory path near the top of File Explorer and type Ctrl-C to ‘copy’ the full directory path into the clipboard.
Go back to Visual Studio and right-click on the ‘WebAppMaterialize.Server project in Solution Explorer and click ‘Publish…’.
Choose ‘FolderProfile’ then click on the ‘Configure…’ link.
Click within the Target location box and type Ctrl-V to ‘paste’ in the directory path.
Add ‘/publish’ (without quotes) to the end of the path and press the ‘Save’ button.
Once this process completes, return to the File Explorer. There should be a new directory called ‘publish’ containing about 50 files and three directories. This completes the local publish or build step.
Creating a Docker Image
This step creates a Docker image from the publish directory. It uses Docker client commands within a PowerShell environment.
Launch PowerShell from the Windows Start menu.
Confirm that Docker is correctly installed by using the ‘docker version’ command. If successful, it will report on Client and Server configuration.
Enter ‘cd “’ (cd with one double-quote) and right-click to paste in the project directory from the previous step. You may have to return to the File Manager if this is not still in your copy buffer.
Add ‘”’ (a closing double-quote) and press enter.
Enter the ‘ls’ command. Verify that the file called ‘Dockerfile’ (no extension) is in the listing.
Enter the command ‘docker build -t webappmaterialize .’ (note the trailing ‘.’)
Docker will now pull a Docker image from Microsoft and copy the executables from the publish directory to create a new Docker image.
Enter the ‘docker images’ command.
The last command should produce the following output:
Once the Docker image has been created successfully, it can be deployed and run from any Docker client (on your local development machine or redeployed to the Docker host in DAIR). The newly built Docker image can be executed using the following command:
‘docker run -p 8000:80 --rm -it webappmaterialize’
It will produce the following output :
Hosting environment: Production
Content root path: /App
Now listening on: http://[::]:
Application started. Press Ctrl+C to shut down.
At this point you will be able to run A-DAT from a browser from the URL: ‘localhost:8000’
To stop this process, use Ctrl-C.
Apption Data Assessment Tool User Guide
Once successfully deployed, the application is accessible by entering its URL in a web browser. You will be directed to the A-DAT landing page, which looks like the following image.
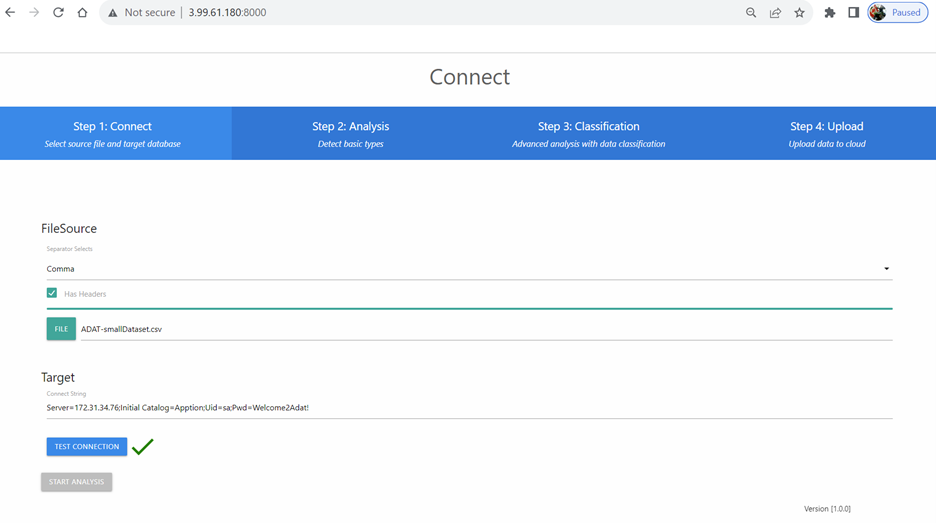
Step 1: Connect
This is the landing page of the app where the user enters information about the source data file and target database. The “Start Analysis” button will only be enabled once a data source file has been uploaded. It is important that the user also determine what separator is used in the file and whether the file contains header information.
The target database is not mandatory but must be specified if you wish to upload the data from the file into your database. You must specify the internal database IP in the Target Connection String since you are connecting from within the cloud network. You can determine the internal (or private) IP of your DB from the EC2 Instance summary page in AWS.
The data may still be run through analysis only (not uploaded to the DB) if desired.
Once you have completed entering the required information, click the “Start Analysis” button to begin the analytics process. The following page is an example of what will be displayed once the initial analysis has completed.
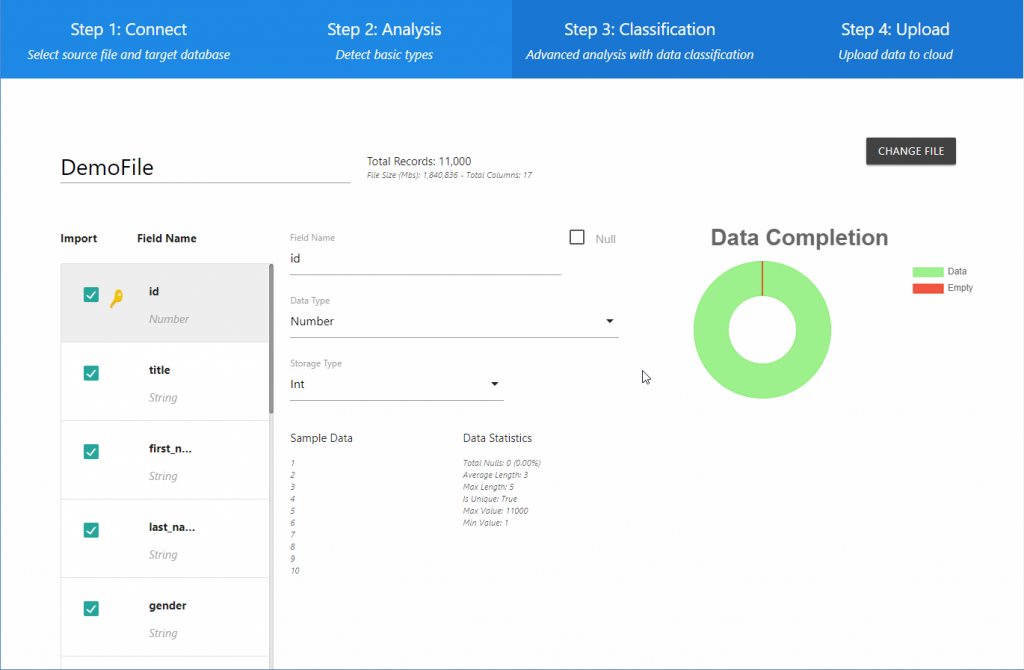
Step 2: Analysis
The “Analysis” screen displays the results of the initial pass through the data. In this section, all the fields are listed on the left side of the screen. Detailed information for a selected field will be displayed on the remaining part of the screen. This can include field name, basic data type (String or Number), and the potential storage type. Statistics and sample data from the analysis are displayed on the right side for consideration where data uniqueness is also determined. The initial pass provides a simple schema should you choose to use it. Some users may wish to classify fields in more detail, and therefore would move on to the next step by clicking the “Classify Fields” button (not shown) at the bottom of the field list on the left. Once the classification analysis is complete, the following screen should appear:
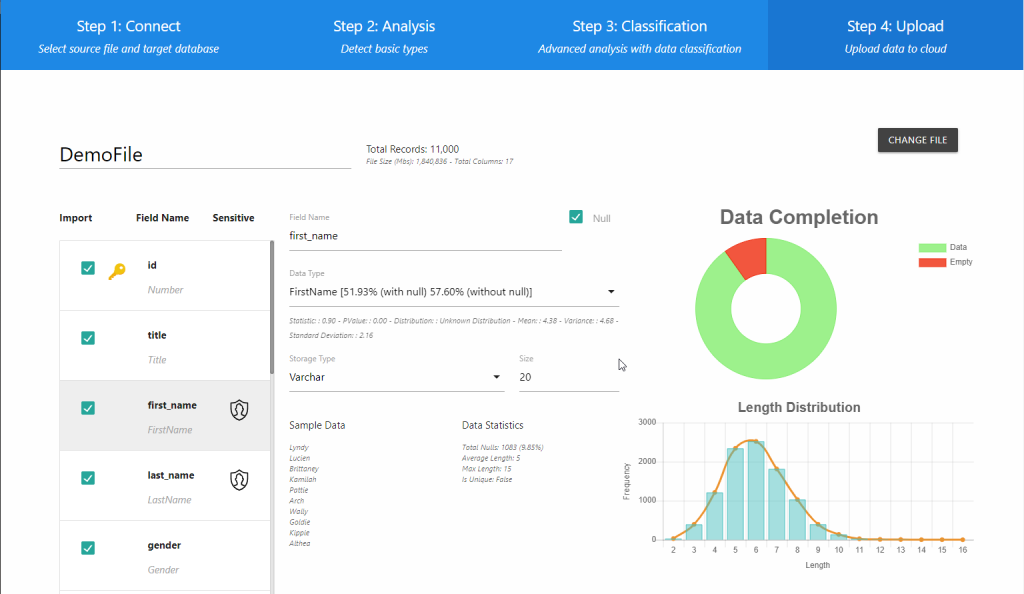
Step 3: Classification
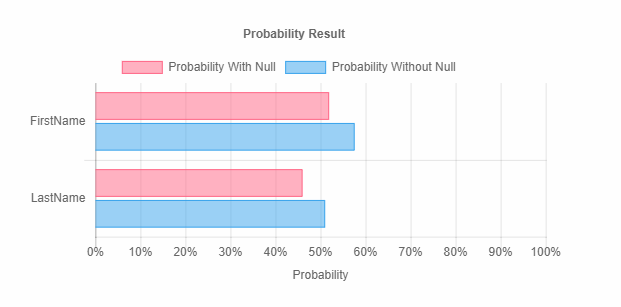
The field list on the left will now have a more accurate interpretation of each field. The application identifies the specific type of data for each field and indicates to the user if a field contains potentially sensitive information by placement of the icon in the Sensitive column. The “Data Type” drop down list contains all potential data types ranked by probability. More data statistics are introduced as well as new graphs giving a visualization of the data in each field. Scrolling down will reveal a data type probability graph as well. The image below is an example of the probability graph for a FirstName field.
At this point, the user has the ability to make any number of adjustments at the field or file level, such as:
Change the table name for the database
Select which fields should be imported
Change the field names
Change the data type if necessary
Change the storage type (used for the schema generation)
Toggle primary key settings for unique fields
Select whether fields are nullable
Once the changes are made, simply click the “View Schema” button to progress to the final section of the data transport process.
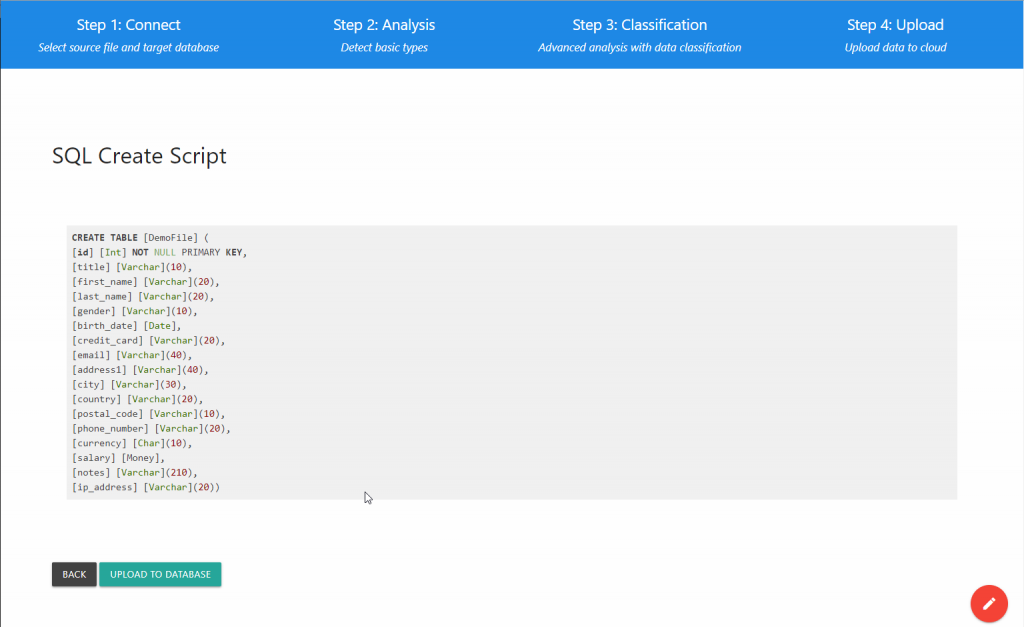
Step 4: Upload
Termination
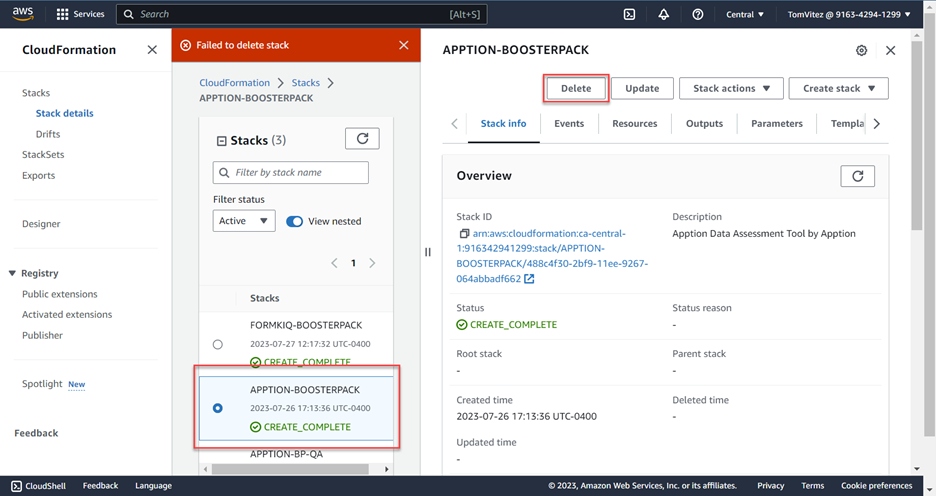
Once you have completed ‘using the application’ and uploaded your data to your database, simply close the browser tab to terminate the application. To free up DAIR Cloud resources, you must delete the Stack instance and Container(s) you created. To clean up both Host and Containers at once, navigate to the CloudFormation > Stacks page in AWS, select the Stack you wish to delete, and then click Delete.
Solution Considerations
Data Architecture
The solution is self-contained and only requires a SQL server database to upload the selected file to a database. The schema for the database is generated by the application and there are no other database dependencies.
Security & Network
The solution relies on proven .Net core security (ASP.NET Core, Blazor) and the other security considerations depend on the network configuration of the deployment. A single port inbound is required to access the application through HTTPS. It is recommended to set up the target database within a private network to limit the open ports in the firewall.
The application server should have its firewall settings configured to allow connectivity to the database servers. For testing purposes, if the SQL server and application are running on separate Docker containers, ports 80 and 1433 would need to be exposed so that the containers are able to communicate with each other.
Scalability
The solution is designed to use multiple cores and effectively use the CPUs to balance the work-load. The smaller the file, the faster the processing and uploading of the file. The data upload to the database uses bulk loading to optimize the insertions. However, this mode can be changed in the code to use standard inserts and to accommodate different database configurations.
Availability
The application uses standard web infrastructure and can leverage firewalls and load balancers to increase availability using multiple servers.
User Interface (UI)
The user interface is built using Materialize (https://materializecss.com) and any desired UI changes would need to use Materialize to design these changes. It is possible to introduce other open source design interfaces such as Bootstrap, however this would prove challenging as it follows different CSS standards.
API
The strength of the application lies in its ability to analyze fields and determine the datatypes of these fields. Currently 30 different data recognizers are provided in the solution.
To extend the API with additional data recognizers, the users can add a new class in the recognizers project (called RecognizerTools). The instructions below allow users to add new data recognizers:
Copy and paste the TemplateRecognizer.cs, and give it your desired name
Open the your new Recognizer, change the class attributes (StorageTypes) to any potential StorageType of this recognizer and change the return value inside the GetDescription() function with the name of the Recognizer
Change the implemented interfaces by the characteristics of the new Recognizer
You must choose one of the basic interfaces, you can choose one or more than one of the length interfaces. Choose the Sensitive interface depending on the type of the Recognizer
Implement the matching algorithm inside the ValidateData() function
(Optional) – Customize your graph data by changing the GetStatus() function and replace your own way of collecting data with IncrementStats() function
Look into MoneyRecognizer.cs for more details
By default, the length of the data is collected
Add your new DataType to the DataType enumeration types (DataTools.ColumnMetadata.cs)
For example, if you add a MoneyRecognizer, then add “Money” to the DataType enums.
7. Add `RegisterRecognizer<XXXRecognizer>(“XXX”, DataType.XXX); ` inside the RegisterRecognizers() function (RecognizerTools.SecondPass.cs) where XXX is your previously created DataType’s name
Cost
In a development environment, it is estimated that the solution will cost around $100/month assuming that the database and web server are hosted on an EC2 T2 Large image and run continuously.
On a production environment, it will be necessary to add more nodes and enable load balancing. Each additional node (EC2 T2 Small) will add a cost of approximately $20/month.
License
The license of the project is The Mozilla Public License v2. All the dependent libraries from Nuget are under compatible licenses.