Accueil / Solution type : Une plateforme en nuage de renseignement géospatial avec apprentissage automatique
Bien que le programme ATIR n’accepte plus les demandes pour les ressourcesennuage, vousaveztoujoursaccès aux Propulseurs et à leur documentation, qui serontpréservés et bénéficieront d’un soutienjusqu’au 17 janvier 2025.
Après le 17 janvier 2025:
Les saisies d’écran devraient rester fidèles, mais au lieu de vous connecter à votre compte ATIR dans AWS quand on vous le demande, vous devrez vous connecter à un compte AWS personnel.
Les liens vers les scripts CloudFormation d’AWS permettant le déploiement automatique de l’application type devraient rester les mêmes et être fonctionnels.
Les liens vers les dépôts GitHub permettant de télécharger le code source du Propulseur resteront valables puisque c’est le créateur du Propulseur (celui qui a élaboré les applications de source ouverte servant d’exemple) qui en est le propriétaire et en assure le maintien.
Le Propulseur GAIT (Geospatial-AI lnformation Toolbox)
Une plateforme en nuage de renseignement géospatial avec apprentissage automatique.
La Solution type du Propulseur GAIT (Geospatial-AI lnformation Toolbox) est une plateforme en nuage de renseignement géospatial avec apprentissage automatique (AA). Elle montre comment Ecosystem Informatics Inc. a bâti une plateforme en nuage modulaire et adaptable pour servir d’alternative aux logiciels commerciaux plus onéreux.
Énoncé du problème
Beaucoup d’applications intelligentes utilisant les mégadonnées et pourvues de capacités associées au renseignement géospatial recourent à de multiples éléments d’infrastructure comme une base de données pour stocker ces dernières, des dépôts de code source pour l’intelligence artificielle (IA) et d’autres modules de traitement des données, un moteur de visualisation pour reporter les données géospatiales sur une carte et ainsi de suite.
On a nettement besoin d’une plateforme en nuage de source ouverte réunissant plusieurs de ces éléments de base, assortie d’une architecture de microservices qui autoriserait la mise à l’échelle et la modularité des différents composants. Parallèlement, on doit pouvoir intégrer et déployer le code efficacement dans le nuage. Plusieurs types d’entreprises et d’industries éprouvent ce besoin.
Les méthodes classiques pour y arriver comprennent l’installation séparée des composants requis, tâche à la fois laborieuse et onéreuse quand il faut recourir à des logiciels commerciaux et à des services de données. Par ailleurs, les applications qu’utilisent les analystes SIG interdisent souvent le partage et l’exploitation des données à cause de la façon dont celles-ci sont formatées. On pourrait opter pour plusieurs applications indépendantes, mal intégrées, ou pour des applications qui le sont extrêmement tel ESRI, avec des plans SaaP et DaaP coûteux, susceptibles de rebuter les jeunes entreprises.
La Solution type est gratuite. De source ouverte, elle a été conçue pour être souple et comprend un algorithme AA modulaire qui analyse directement les données. Les formats de données employés peuvent être exportés vers plusieurs logiciels de cartographie comme ArcGIS, Google Maps ou QGIS. Affranchie du format des données, la plateforme non seulement simplifie le déploiement, mais facilite aussi l’intégration avec d’autres logiciels de source ouverte tout en réduisant l’obstacle financier que représente le lancement de produits qui ont besoin d’un SIG pour gérer les données, les traiter et prendre des décisions.
Aperçu
La Solution type comprend un moteur dorsal qui incorpore ce qui suit :
l’apprentissage automatique;
des modules pout analyser et visualiser les données géospatiales;
une application frontale pour le déploiement sur le Web;
une base de données fusionnée avec Docker pour les interventions sur les données;
une architecture de microservices sous forme de conteneurs.
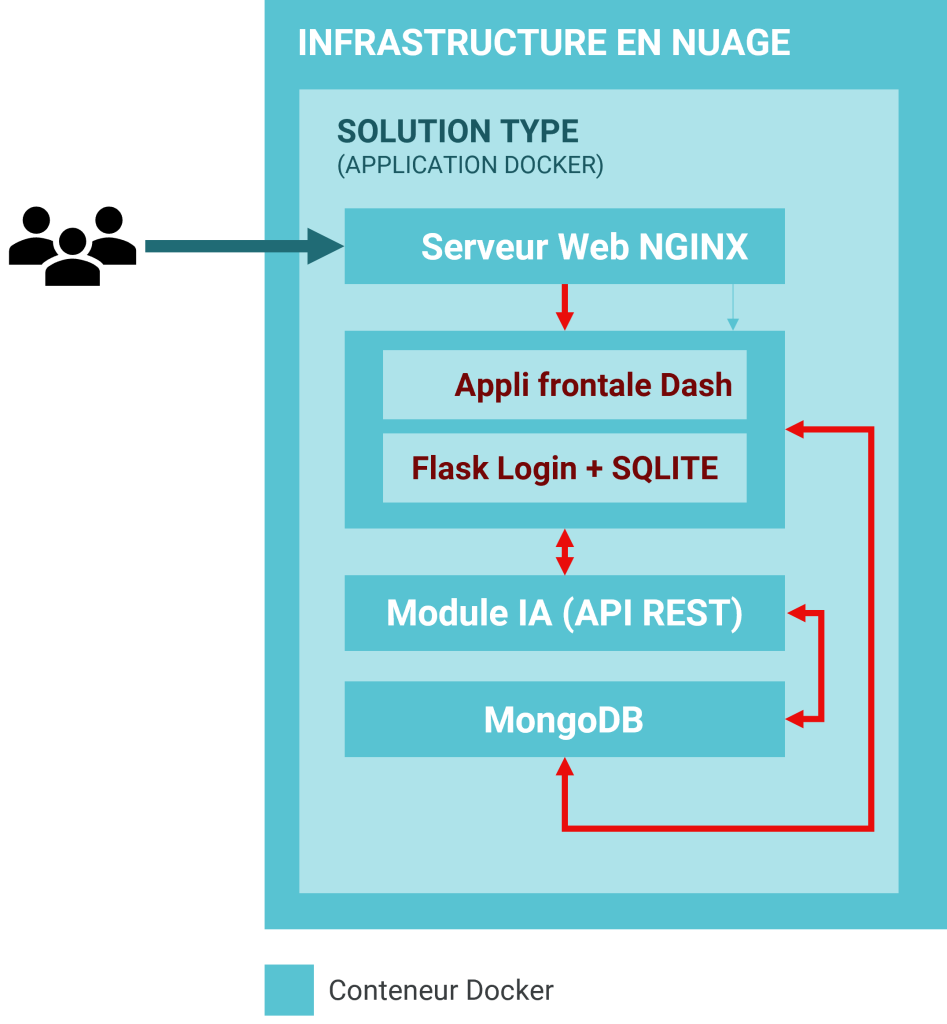
Diagramme de la Solution type
La structure de la Solution type est illustrée dans le diagramme qui suit.
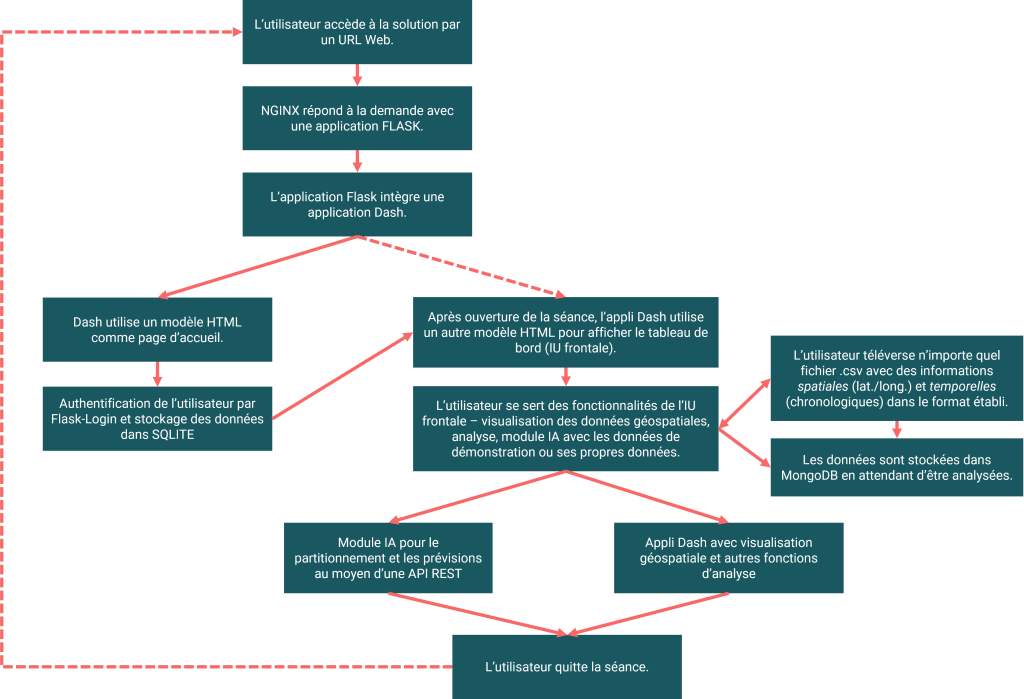
Cloud Infrastructure
WORKFLOW
Description des éléments
Voici un résumé des principaux composants de la Solution type.
Une application Flask en Python incluant ce qui suit.
Un module frontal bâti avec Dash de Plotly (en Python). Il est à la base de l’analyse des données et de leur visualisation géospatiale. Dash présente plusieurs avantages : ses applications s’exécutent dans un navigateur Web; on peut aussi les déployer sur des machines virtuelles ou des grappes Kubernetes puis les partager avec un URL. Puisque ses applications sont visionnées dans le navigateur Web, Dash est par définition adapté à une variété de diverses plateformes et aux applications mobiles.
Un module d’accès Flask-Login (en Python) et une simple base de données SQLITE pour stocker les données servant à authentifier l’utilisateur. Ce module pourrait être remplacé par un système d’accès plus complexe comme Auth0, Okta ou AWS Cognito, ou par un module d’authentification JWT créé sur mesure.
Un module d’apprentissage automatique (en Python) venant avec deux algorithmes distincts.
Un algorithme supervisé (ANN avec LSTM)
Un algorithme sans supervision (partitionnement en K-moyennes)
Ces algorithmes pourraient être remplacés par d’autres ou on pourrait les adapter encore plus en fonction de l’application (tant et aussi longtemps qu’on ne modifie pas le format des entrées et des sorties).
MongoDB, un module à base de données NOSQL pour stocker les données
MongoDB fonctionne n’importe où, sur un ordinateur portable comme dans un centre de données, ce qui le rend extrêmement souple. MongoDB propose aussi une solution en nuage à gestion intégrale permettant de bâtir plus vite les applications et de les développer davantage. Plusieurs bibliothèques Python interagissent avec la base de données Mongo (pymongo, utilisée dans la Solution type, est la plus populaire)
Un module pour serveur Web reposant sur NGINX, logiciel de source ouverte pour les services Web, la procuration inversée, la mise en antémémoire, l’équilibrage de la charge, le visionnement en continu et plus.
D’abord conçu comme serveur Web pour une performance et une stabilité maximales, ce logiciel est devenu extrêmement populaire en raison de son empreinte légère et de sa capacité à s’adapter à un matériel minimaliste.
Les composants qui précèdent sont tous emballés dans une architecture de microservices reposant sur Docker, logiciel permettant de créer un conteneur distinct pour chaque service (interface frontale, IA, Mongo, NGINX), d’où son avantage magistral : la portabilité
Après avoir testé l’application en conteneur, vous pourrez la déployer dans n’importe quel système sur lequel fonctionne Docker et être sûr que l’application s’exécutera exactement comme quand vous l’avez essayée.
La portabilité et la performance qu’assure la mise en conteneurs rendront le processus de développement plus agile et plus réactif. Améliorer en permanence les processus d’intégration et d’exécution afin de profiter des conteneurs et de la technologie, comme les Enterprise Developer Build Tools pour Windows, vous permettra d’installer le logiciel adéquat au moment voulu.
Le conteneur Docker renfermant une de vos applications inclura aussi les versions pertinentes du logiciel dont elle a besoin. Que d’autres conteneurs Docker abritent des applications maison nécessitant une version différente du même logiciel ne soulève donc aucune difficulté; les conteneurs Docker sont totalement indépendants les uns des autres.
En traversant les différentes étapes du cycle de développement, vous n’aurez donc aucune crainte que l’image créée fonctionne autrement que lors des essais, jusqu’à ce que vous la proposiez éventuellement aux utilisateurs.
Si la demande l’exige, il est possible de créer rapidement de nouveaux conteneurs pour vos applications. Une gamme d’options permet de gérer l’usage de multiples conteneurs. Parcourez la documentation de Docker pour en savoir plus.
Ce que vous devriez avoir fait avant de déployer la solution type
Avoir créé une règle de groupe de sécurité vous donnant accès aux machines virtuelles (MV) du Nuage de l’ATIR à partir de l’adresse IP utilisée, par le protocole SSH (port 22 du protocole TCP).
Avoir créé la paire de clés SSH (biclé) avec laquelle vous vous connecterez à vos MV de l’ATIR.
Vous aurez besoin d’un compte sur l’ATIR pour déployer le Propulseur GAIT dans le nuage. L’application est déployée sur une instance Linux.
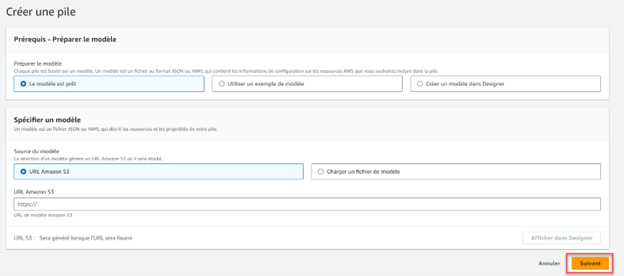
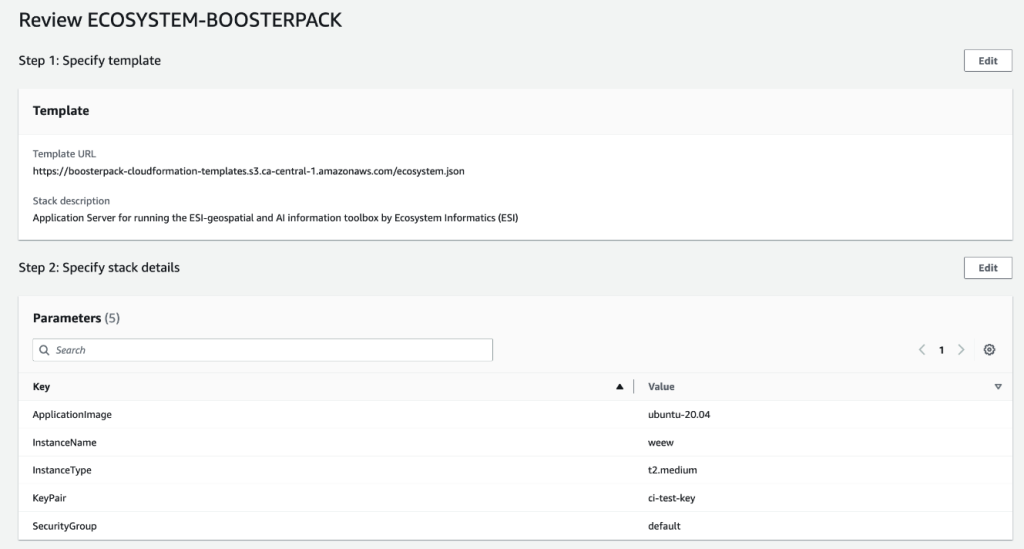
De la page du Catalogue des Propulseurs de l’ATIR, allez au Propulseur d’Ecosystem Informatics puis cliquez DÉPLOYER pour le lancer avec la pile AWS CloudFormation.
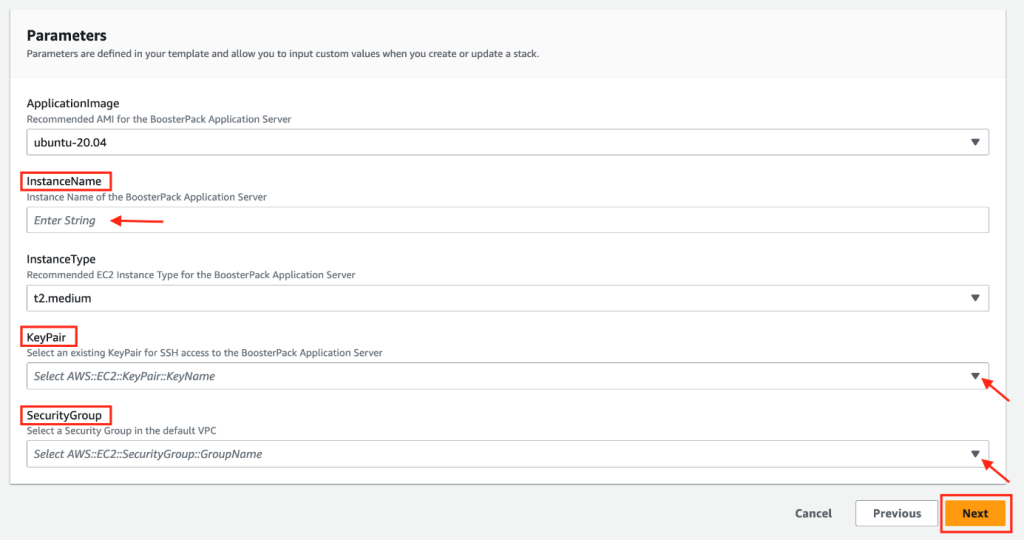
Cela fait, cliquez Suivant pour passer à la deuxième étape de Cloudformation et remplissez le formulaire de configuration. Dans le champ InstanceName, donnez un nom unique à l’instance de votre serveur d’application, puis complétez le formulaire avec les menus déroulants. Veuillez noter que certains paramètres comme ApplicationImage et InstanceType sont déjà configurés et ne peuvent être modifiés.
Cliquez SUIVANT pour passer à la troisième étape de CloudFormation. Cette partie concerne la configuration d’options avancées ou supplémentaires, inutiles dans le cas qui nous intéresse. Cliquez simplement Suivant au bas de la page pour sauter cette étape et passer à la quatrième et dernière de CloudFormation.
La dernière partie vous permet de vérifier la configuration actuelle du Propulseur et d’y apporter des modifications avec le bouton Modifier, si vous le désirez. Une fois que la configuration vous convient, cliquez Soumettre, au bas de la page, pour déployer le Propulseur.
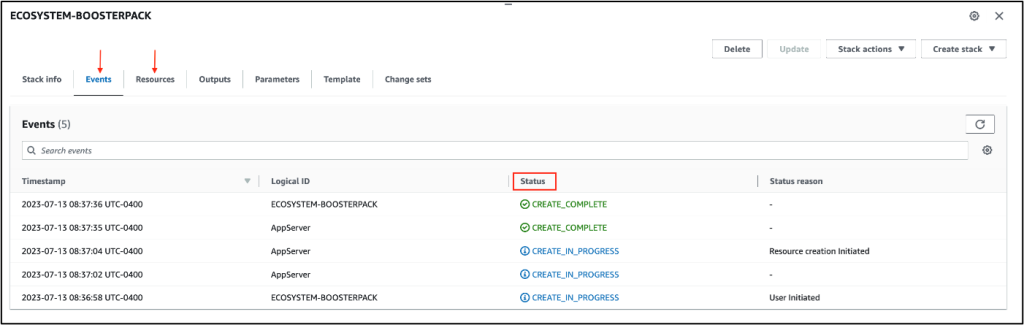
Le déploiement commence par la création d’une nouvelle instance. Le reste est automatique. Suivre le développement de l’instance AWS n’est possible qu’avec les onglets Événements et Ressources de la console CloudFormation. Pour vérifier l’avancement du déploiement, vous devrez donc vous connecter au serveur de l’application.
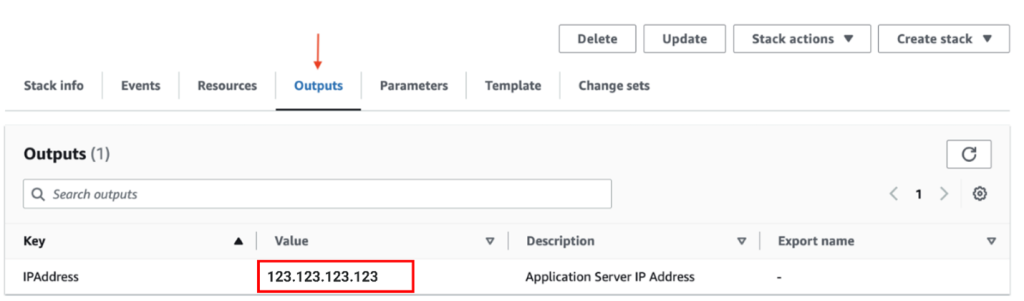
Remarque : notez l’adresse IP qui apparaît sur l’onglet Sorties de la page CloudFormation du Propulseur. Il s’agit de l’adresse IP externe de l’instance qui vient d’être créée. Vous en aurez besoin pour accéder à l’interface web de l’application ou vous connecter au serveur par le protocole SSH.
Lancement
Connectez-vous au serveur de l’application à partir d’une coquille ou d’un terminal utilisant le protocole SSH avec la commande suivante :
>ssh -i key_file.pem ubuntu@IP
Remplacez « key_file » par la clé privée de la biclé SSH choisie sur le formulaire des paramètres de configuration CloudFormation et remplacez « IP » par l’adresse IP fournie, que vous avez précédemment notée.
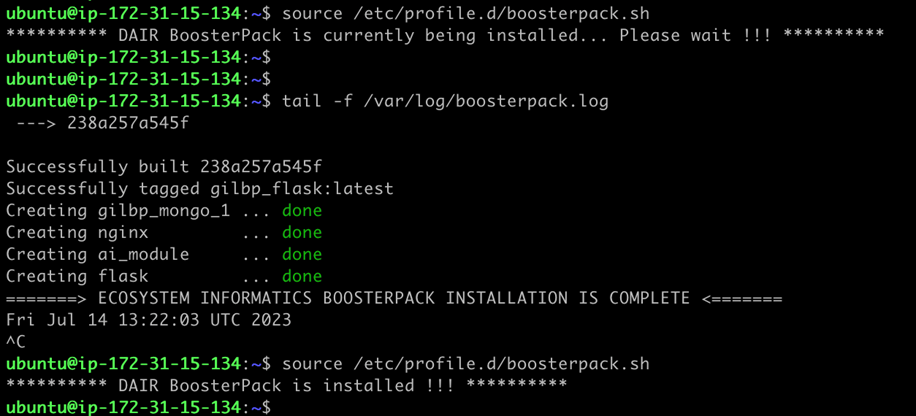
Une fois la connexion avec le serveur de l’application établie, vous pourrez suivre le déploiement du script d’automatisation avec les commandes que voici :
>source /etc/profile.d/boosterpack.sh
>tail -f /var/log/boosterpack.log
Le déploiement dure en moyenne dix à quinze minutes, script d’automatisation inclus. L’application démarre automatiquement après l’instanciation.
Pendant ce temps…
Allez à la page de configuration des groupes de sécurité dans AWS afin d’ajouter des règles entrantes au groupe par défaut sélectionné lors du paramétrage de la console CloudFormation.
Assurez-vous que le groupe de sécurité choisi pour cette MV comprend des règles entrantes qui donneront accès au port 22 (SSH) et au port 80 (HTTP) à partir de l’adresse IP externe, afin que vous seul puissiez accéder à la MV.
Pour vérifier si l’application du Propulseur a été déployée et fonctionne correctement, exécutez la commande Docker qui suit sur le terminal du serveur de l’application :
>docker images
>docker ps
Pour accéder à l’interface utilisateur, saisissez l’adresse IP externe dans un navigateur avec le port désigné (port 80) comme suit :<adresse.IP.externe>:80
Identifiants par défaut
Nom d’utilisateur : admin_test
Mot de passe : password
Courriel : admin@sample.com
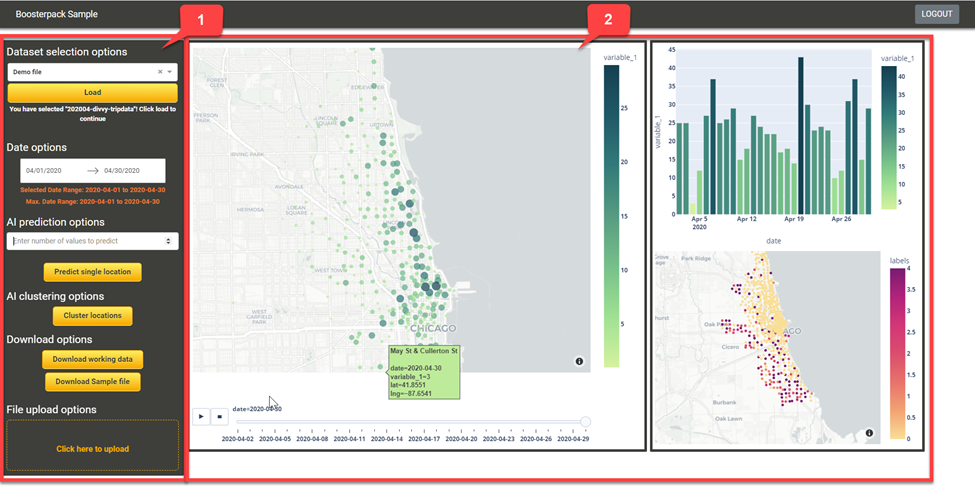
Survol de l’application
La saisie d’écran ci-dessus illustre l’interface utilisateur avec le panneau de commande fonctionnel, à gauche, et la visualisation, à droite. Dans cette dernière, l’étiquette variable_1 correspond à l’entité qu’on souhaite prédire et voir. Elle fait partie du type de fichier qu’il faut téléverser, mais peut représenter n’importe quoi, selon les données qui ont été emmagasinée. S’il s’agissait d’immobilier, par exemple, variable_1 pourrait correspondre au prix des habitations; en sciences policières, elle pourrait représenter le nombre de cambriolages.
Cette application pour navigateur effectue plusieurs fonctions importantes, décrites en détail plus bas.
(1) Panneau de commande fonctionnel
Menu déroulant Dataset Selection et bouton Load
Ils permettent de choisir le jeu de données sur lequel l’utilisateur souhaite travailler. Cliquer le bouton Load charge le jeu de données en question dans l’application.
Fichier Demo
Ce fichier fait partie de la Solution type. C’est lui qui sert d’échantillon par défaut quand on utilise les identifiants mentionnés plus haut. Après ouverture de la séance, l’utilisateur peut, à son gré, choisir le fichier Demo dans le menu déroulant et en charger le données avec le bouton Load ou téléverser ses propres données dans le format indiqué (voir le tableau ci-dessous). Après téléversement, on charge le fichier en le sélectionnant dans le menu déroulant.
Le fichier Demo rassemble les données publiques sur les déplacements effectués avec Divvy, réseau de bicyclettes collectives de la région de Chicago. Les données viennent du site https://ride.divvybikes.com/system-data.
Ces données sont constituées comme suit :
Données spatiales
Station de départ (nom, ID, latitude et longitude)
Station d’arrivée (nom, ID, latitude et longitude)
Données temporelles
Journée et heure de départ
Journée et heure d’arrivée
Autres données
Type d’utilisateur (membre, voyage unique, passeport quotidien)
Les données ont été modifiées pour que leur format convienne à cet outil (voir ci-dessous).
lat
lng
variable_1
varriable_1_id
variable_1_name
date
ZZZ
ZZZ
ZZZ
ZZZ
ZZZ
ZZZ
Dans notre exemple :
lat and lng – latitude et longitude de la station de départ;
variable_1 – nombre de déplacements ayant la même station comme point de départ;
variable_1_id – numéro d’identité de la station;
variable_1_name – nom de la station;
date – date correspondant au nombre de déplacements effectués à partir de cette station.
Date Options
Permet à l’utilisateur de choisir une plage de dates dans les données chargées. Cette fonction permet d’analyser ou de visualiser les données d’après telle ou telle date, si on le désire.
AI prediction options
On peut recourir à plusieurs algorithmes IA pour analyser les données spatiales et temporelles. La Solution type applique la technique fondamentale du réseau neuronal pour prédire les valeurs futures de la série chronologique à partir des valeurs existantes. L’application permet à l’utilisateur de saisir n’importe quel entier comme valeur, c’est-à-dire le nombre de futurs points dans la série chronologique que doit prédire l’algorithme IA. En cliquant le bouton, la visualisation (les graphiques) sera automatiquement actualisée en fonction du nombre saisi.
On peut se servir des prévisions IA de deux façons.
En sélectionnant une bulle quelconque sur la carte pour prévoir le nombre de déplacements futurs (variable_1) partant de cette station (variable_1_id)
En traçant une zone incluant de nombreuses bulles avec l’outil de dessin polygonal sur la carte pour prévoir le nombre de déplacements futurs (somme des variable_1 des bulles ou stations) dans la zone sélectionnée
AI clustering options
Divers algorithmes IA permettent d’analyser les jeux de données spatiales et temporelles. L’un d’eux est l’algorithme de partitionnement par k-moyennes. Le partitionnement est le procédé qui consiste à diviser une population ou un ensemble de points de données en nombreux groupes afin que les points de données du groupe A se ressemblent plus entre eux qu’aux points de données des groupes B à Z.
L’idée est de séparer les valeurs aux propriétés similaires afin de créer des groupes. L’algorithme k-moyennes cherche les données analogues, la variable k correspondant au nombre de groupes à créer. Le partitionnement nous aide à mieux comprendre les données en les réunissant ou en les séparant en groupes. Le partitionnement par k-moyennes peut s’appliquer à tous les domaines, ou presque, des transactions bancaires aux moteurs de recommandation, en passant par la cybersécurité, l’assemblage de documents et la segmentation des images.
Avec le fichier Demo, l’algorithme analyse les données sur les trajets à bicyclette, ce qui procure de précieux renseignements sur la circulation urbaine et permet de planifier les villes de demain. Dans la Solution type, l’algorithme a été conçu pour partitionner la variable1_id, donc en établir l’emplacement d’après la variable_1. Quand on l’exécute, on obtient une carte (expliquée plus bas) illustrant comment les variable_1 ID sont groupées. Ceci aide à établir les emplacements dont les caractéristiques se ressemblent en vue d’une analyse plus poussée et aux fins de planification.
Download sample file
Permet de télécharger un fichier CSV pour montrant le format dans lequel les fichiers (renfermant les données personnelles) doivent être présentés afin que l’application puisse s’en servir. Les fichiers qui ne respectent pas ce format ne seront pas traités.
File upload options
Permet de téléverser n’importe quel jeu de données pour analyser, pourvu que les fichiers respectent le format indiqué.
(2) Panneau de visualisation
Carte
Ce graphique montre à l’utilisateur l’information géospatiale que renferme le jeu de données examiné. Les données de la colonne variable_1 apparaissent sous forme de diagramme à bulles. Le rayon des bulles correspond à la valeur de la variable. En d’autres termes, plus la valeur de variable_1 est élevée, plus grosse sera la bulle. On peut aussi visualiser les changements survenus au fil du temps en cliquant la touche de lecture au bas de la carte.
Graphique à barres
Ce diagramme montre les informations temporelles véhiculées par le jeu de données. Il présente la somme des variable_1 pour chaque période couverte (jours, semaines, etc.). Le graphique sera vierge si on clique une des bulles sur la carte.
Présentation des résultats cartographiques
Cette carte diffère de la première en ne présentant que les résultats de l’algorithme IA de partitionnement.
Présentation des résultats graphiques
Cette partie présente les résultats de l’algorithme IA prévisionnel. Elle montre les niveaux actuels et les niveaux futurs prévus sous forme de couleurs distinctes, pour mieux les différencier.
Considérations relatives au réseau
Pour faciliter l’accès http avec le navigateur Web, le port 80 doit être ouvert.
Considérations relatives au coût
L’instance Amazon T2 Medium procure les ressources optimales que requiert l’application. On peut toutefois augmenter ces dernières pour traiter des données plus volumineuses et accélérer le traitement des tuiles de carte en vue d’un calcul et d’une visualisation plus rapides.
Docker Desktop vient avec une licence gratuite (personnelle) ou un abonnement (professionnel, équipe, entreprise). Pour en savoir plus, visitez la page de Docker sur les licences d’exploitation ici.
Termination
Quand vous aurez fini d’explorer la Solution type, arrêtez l’application afin de libérer les ressources en nuage pour les autres membres de l’ATIR.
Revenez à la page Piles de la console CloudFormation et supprimez la pile qui correspond au Propulseur.
La solution a été conçue pour être très modulaire et faciliter la mise à niveau. Chaque composant peut être amélioré pour plus de performance, capacité ou envergure.
L’application Dash peut être rehaussée en application Dash pour entreprise (contre rémunération), laquelle offre beaucoup plus de fonctionnalités et de possibilités de visualisation, tout en garantissant une expérience frontale plus intéressante.
N’importe quelle base de données ou service de base de données comme MySQL, Oracle, AWS RDS, etc., pourra remplacer le module correspondant de la solution.
Sécurité
Avant d’utiliser l’application web dans un environnement de production, il convient de se procurer et d’installer un certificat HTTPS valide.
La Solution type recourt à une simple méthode d’accès et d’authentification reposant sur Flask-Login pour l’authentification, la gestion de la séance et le stockage des informations sur l’utilisateur dans une base de données SQLITE. Il ne s’agit que de mesures rudimentaires qu’on devrait renforcer avant de passer à la production. Plusieurs options sont possibles, notamment AWS Cognito, Auth0 et Okta.
Ces identifiants sont mémorisés dans la base de données SQLITE, intégrée au code de la Solution type. La base de données se trouve dans le module/dossier Flask sous le nom de fichier data.sqlite.
Aucun identifiant d’administrateur n’est nécessaire pour accéder à la base de données SQLITE, cependant, on aura besoin du logiciel de source ouverte d’un tiers pour voir et modifier la liste des utilisateurs. Nous suggérons DB Browser pour la version 3.12.1 de SQLITE.
Après installation du logiciel, vous pourrez ouvrir le fichier data.sqlite et modifier (puis sauvegarder) les identifiants par défaut.
Remarque : La solution est http mais doit être convertie en https pour des raisons de sécurité et de compatibilité avec les navigateurs.
Mise à l’échelle
Le développement de la Solution type repose sur Docker, plateforme de conteneurisation qui permet d’emballer les applications sous forme de conteneurs distincts qui fonctionneront sur tous les moteurs d’exécution compatibles disponibles. Les conteneurs Docker peuvent être mis à l’échelle de diverses manières.
L’interface a été élaborée avec Dash, qui permet le développement d’une solution complète dans un seul langage (Python). Le tout fonctionne bien parce que la page Web en soi est simple et agile.
API
Le module IA interagit avec les autres modules grâce à une API REST. Un des principaux avantages de celle-ci est qu’elle autorise une très grande souplesse. Les données ne sont pas liées à des ressources ou à une méthode, de sorte que le logiciel peut traiter de nombreuses sortes d’appel, restituer les données dans divers formats et même subir des modifications structurales pourvu qu’on mette correctement en place des hypermédias.
Licence d’exploitation
L’application modèle (Dash/Plotly pour Python) est gratuite. Il s’agit d’un logiciel ouvert que couvre la licence d’exploitation du MIT. L’installer et l’utiliser ne coûte rien. Pour voir la source, signaler un problème ou apporter votre contribution, utilisez notre dépôt Github.
NGINX : les sources et la documentation sont diffusées aux termes d’une licence semblable à la licence BSD à double condition.
Les termes ou expressions qui suivent peuvent apparaître dans le document.
Expression
Description
API
Interface de programmation de l’application
SIG
Système d’information géospatiale : système d’information géographique qui crée, gère, analyse et cartographie des données de toute sorte. Le SIG relie les données à une carte et intègre toutes sortes d’informations descriptives (nature des choses) à un emplacement (lieu où se trouvent les choses).
Conteneur
Unité de logiciel standard comprenant un code et tout ce qui y est associé afin que l’application puisse s’exécuter rapidement et de façon fiable d’une plateforme à une autre.
LSTM
Mémoire longue à court terme (réseau neuronal)
Apprentissage automatique
Cadre permettant de bâtir un modèle sans qu’on doive le programmer
Série chronologique
Données séquentielles prises à des intervalles de temps identiques